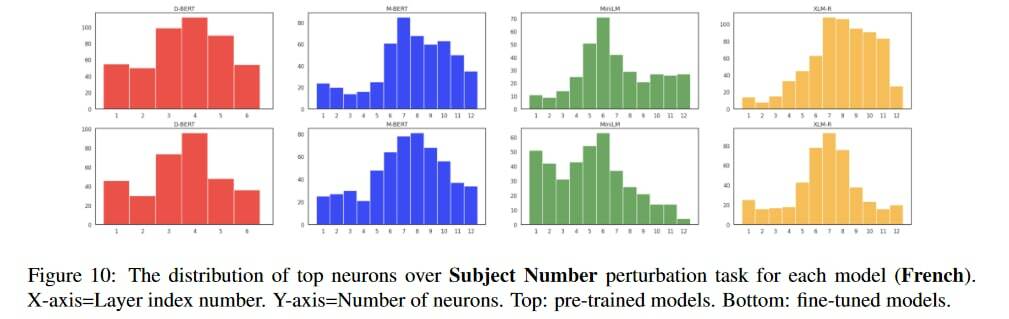
В июне на семинаре SIGTYP при конференции NAACL сотрудник DeepPavlov Олег Сериков с коллегами из Сбера, Вышки и Huawei представят проект MorphCall . Morph Call – это новый набор задач и данных для диагностического тестирования (probing) векторных и языковых моделей для четырех типологически различных языков (английский, русский, немецкий и французский). Morph Call позволяет оценить знание моделей о морфологических признаках слов (число, род, падеж и лицо) и определить чувствительность моделей к различным ошибкам в предложении (например, нарушение согласования между подлежащим и сказуемым).
Все задачи объединены в четыре группы:
* Morphosyntactic Features: способность модели определять наличие того или иного признака у целевого слова (например, обладает ли слово “мыла” категорией числа в предложении “Мама мыла раму”).
* Masked Token: аналог Morphosyntactic Features, в которой наличие признака требуется определить по токену маски, специфическому для токенизатора.
* Morphosyntactic Values: способность модели определять непосредственное значение признака (например, в какой форме числа употреблено слово “мыла” в предложении “Мама мыла раму”).
* Perturbations: чувствительность модели к синтаксическим и словоизменительным ошибкам в предложении.
После проведения анализа четырех мультиязычных трансформеров (mBERT, XLM-R, MiniLM и DistilBERT), используя три взаимодополняющих подхода и сравнивая влияние fine-tuning на задаче частеречной разметки по отношению к качеству на предложенных тестах, оказалось, что модели имеют похожее представление о морфологии для всех языков, а про их чувствительность к ошибкам и влияние fine-tuning читайте в статье.
Текст статьи доступен ссылке.
Репозиторий с кодом и данными доступен ссылке.