
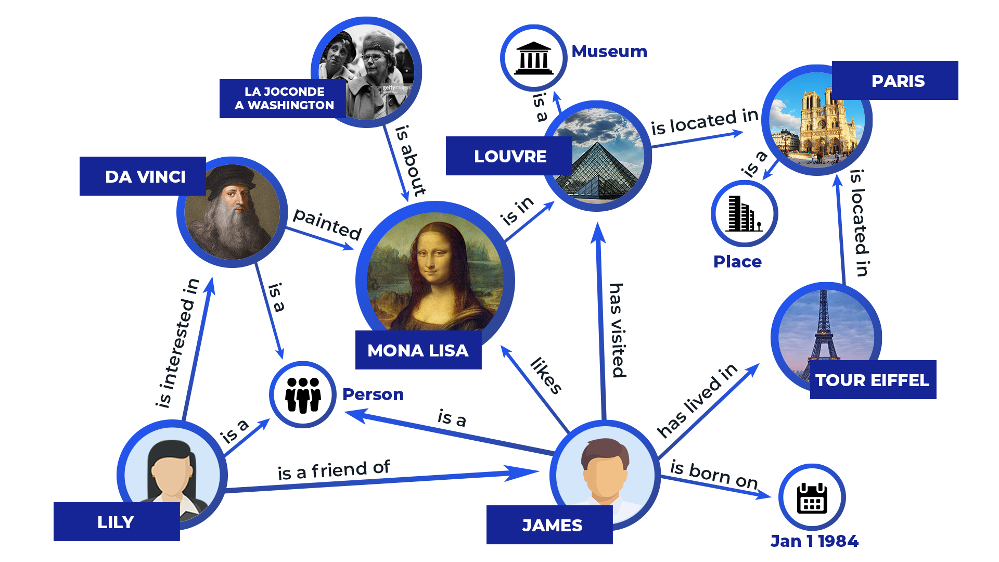
Knowledge graphs (KG) allow us to represent facts about the world in a structured form. Formally they are directed multi-relational graphs that represent structured data by using entities as the graph’s nodes and relationships between entities as the graph’s edges. These graphs might feature information regarding both real-world objects and abstract concepts. To represent KGs, a collection of triplets called (head entity, relation, tail entity) or (h, r, t) is used, each of which has so-called head and tail entities and a relation between them.
Nowadays, KGs are often used in a wide range of applications, including data mining, information retrieval, question-answering (QA), and recommendation systems. Among open-source KGs, the most common are Freebase (based on a variety of public datasets), WN18 (WordNet-based), DBpedia, YAGO, and Wikidata (Wikipedia-based). Apart from this, companies like Google, Amazon, eBay, Uber, and even smaller ones develop their own proprietary KGs to enhance their search, recommendation algorithms, and dialogue and QA systems.
However, the vast majority of knowledge graphs in practice are incomplete. In other words, they lack linkages between actually connected entities. Knowledge graph completion (KGC) techniques attempt to fill up the gaps in a KG in order to overcome this problem. These techniques aim to get novel information about links from KG facts that are already known.
Common approach to Knowledge Graph Completion
To distinguish between true triplets and false triplets, KGC models commonly require learning Knowledge Graph Embeddings (KGE), which are designed to capture structural and semantic information about KG nodes, relations, and the overall internal structure of the KG.
However, it is challenging for these models to perform on a variety of facts connected to abstract and real-world concepts since these embeddings allow a simple scoring function to discriminate between true and false triplets. Therefore, such embeddings should completely include the abundant information encapsulated in a KG.
Furthermore, an increase in the KG size results in a linear rise in model size and inference time when constructing a distinct embedding for each node and relation. Another disadvantage of KGE is that in case of updates in KG it requires complete retraining of embeddings rather than just building up new ones for updated entities or relations.
However, it is challenging for these models to perform on a variety of facts connected to abstract and real-world concepts since these embeddings allow a simple scoring function to discriminate between true and false triplets. Therefore, such embeddings should completely include the abundant information encapsulated in a KG.
Furthermore, an increase in the KG size results in a linear rise in model size and inference time when constructing a distinct embedding for each node and relation. Another disadvantage of KGE is that in case of updates in KG it requires complete retraining of embeddings rather than just building up new ones for updated entities or relations.

Language models for KGC
Another promising direction in the field of KGC is the integration of language models into KGC tasks. Recent large or fundamental language models, such as those of the GPT family, as well as pre-trained language models like BERT and RoBERTa, have shown state-of-the-art performance in the majority of natural language processing (NLP) tasks. Thereby, by treating a triplet in the KG as a text sequence, models like KG-BERT and BERT-RL also managed to compete with traditional KGE models in terms of performance.
Language models generally capture more semantic information from both relations and KG entities than distance-based methods do. As a result, language models can embed previously unknown entities and operate on new facts based on semantic information from triplets’ textual representation.
Language models generally capture more semantic information from both relations and KG entities than distance-based methods do. As a result, language models can embed previously unknown entities and operate on new facts based on semantic information from triplets’ textual representation.

Generative LM for KGC
Recent rise of generative language models signifies a profound advancement within the realm of artificial intelligence. These models, exemplified by state-of-the-art architectures like GPT-3 or T5, have emerged as exceptional tools capable of generating coherent and contextually relevant text that closely mimics human writing. The potential applications of generative language models span a wide range of fields, including automated content creation, language translation, and dialogue systems. Furthermore, their ability to learn and adapt from diverse inputs positions them at the forefront of intelligent systems. And tasks related to KG are no exception.
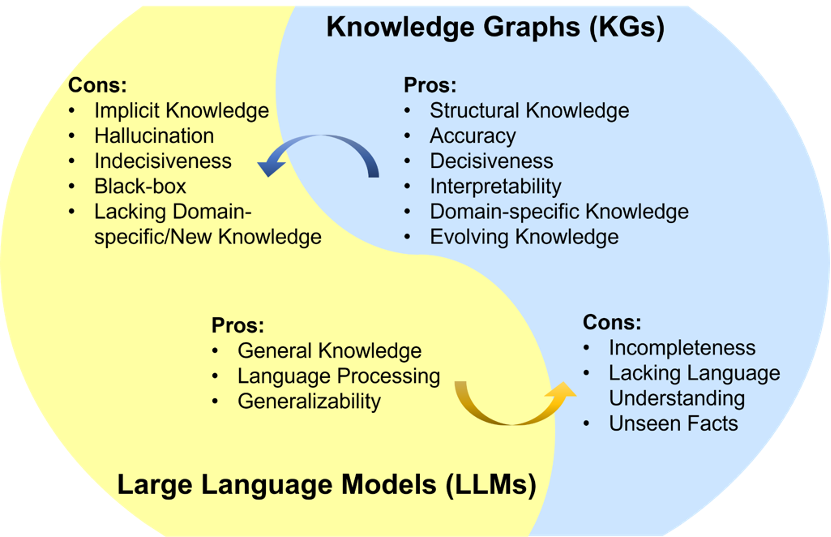
In the field of KG it works in both ways: incorporating KG during training or inference can improve the quality of LM’s generation and help to get rid of hallucinations specific to LLM by incorporating a knowledge base. And vice versa, LMs are able to incorporate complex semantic relations that form the structure of KGs and therefore help with KG completion, KGQA, and other tasks. The focus of this article is on the second direction of enriching KGC methods using generative LMs.
Incorporating neighborhoods in generative LMs
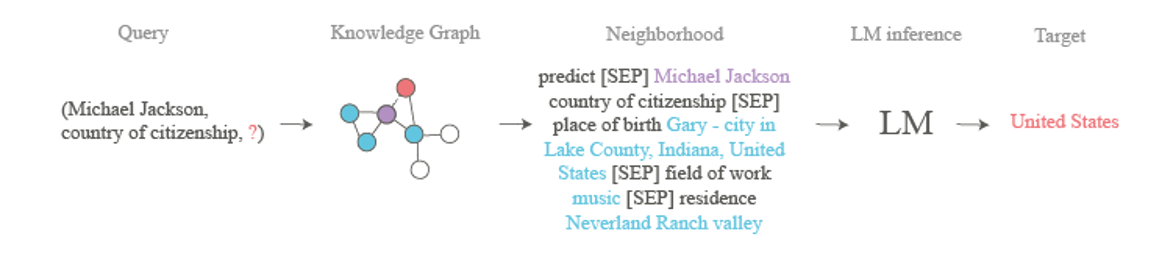
Only data that can be retrieved from language model parameters is used by current language model-based approaches (KG-BERT, BERTRL, KGT5). Therefore, we propose a strategy that uses both internal language model knowledge and external data from KG, given that the KG itself and its structure are accessible. We propose extracting nodes and relations adjacent to h from the KG, i.e. its neighborhood, for the link prediction query (h, r, ?). The neighborhood of the node h better represents the head node itself: Gary - city in Lake County, Indiana, United States contained in the neighborhood for the triplet (Michael Jackson, country of citizenship,?) as shown on a figure may provide hints about the target tail node:
To test this approach we used Wikidata5M dataset, which is one of the largest transductive benchmarks collected in the real-world wikidata knowledge base. A convenient way to access many KG datasets, including Wikidata5M, is the pykeen python library:
from pykeen import datasets
dataset = datasets.Wikidata5M()For the LM part of the pipeline we used the T5 model trained on KGC tasks on the Wikidata5M dataset. Also, we tested OpenAI GPT-4 on this task to compare performance of the model trained specifically for KGC task against the world knowledge of the powerful large-scale model represented recently (i.e. perform knowledge probing on GPT).
Our solution’s pipeline
Formally, the link prediction task is formulated as follows: for each triplet from KG, a model needs to predict tail and head entities in the so-called direct (entity1, relation, ?) and the inverse (?,relation, entity2) queries, respectively, that correspond to this triplet.
We posed this task as a seq2seq problem and solved it using the T5 language model.
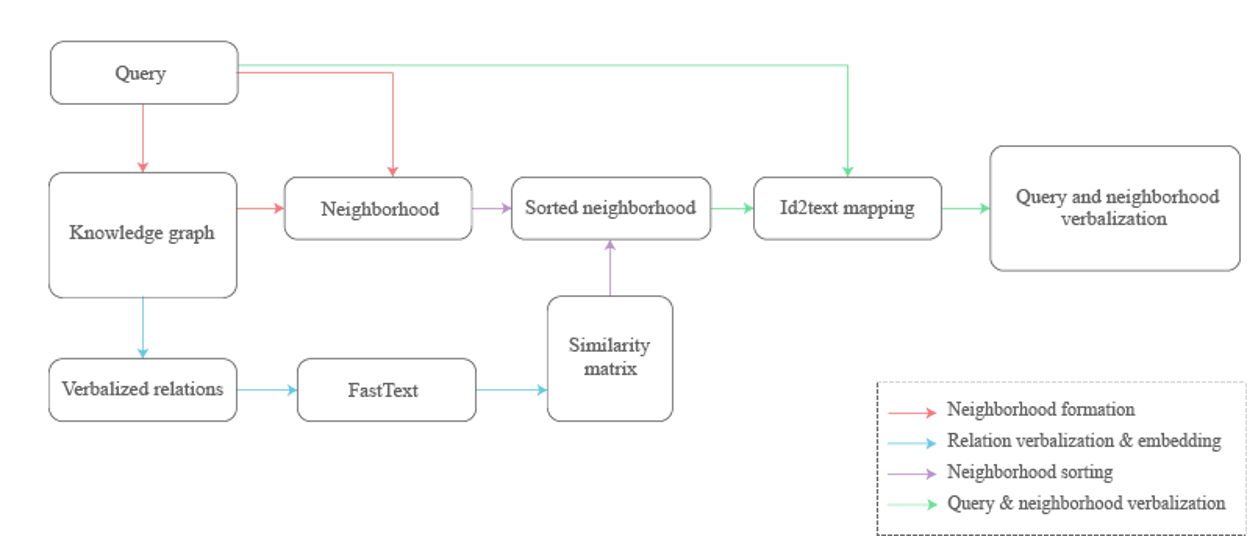
To generate input for the model, we converted inverse and direct queries for each triplet into a text form. Apart from queries verbalization only, as it was done before, we formed a neighborhood for the node and a relation for each query from the KG to provide a meaningful context about graph structure to the model. Thus, verbalized queries and their neighborhoods in the textual form were fed to the input of the T5 for training and then for predicting incomplete triplets during inference:
verbalizer.verbalize("Q1053299", "P159")
# Output: 'predict [SEP] CRH headquarters location [SEP] inverse of owned by Ancon 0 [SEP] instance of business [SEP] legal form joint-stock company [SEP] stock exchange London Stock Exchange [SEP] stock exchange New York Stock Exchange [SEP]'
Overall, a developed pipeline of solving KGC task with T5 model using neighborhood information as an additional context looks as follows:
- neighborhood formation for direct and inverse (entity1, relation, ?) queries, and (?,relation, entity2) for each triplet from the KG;
- query and its neighborhood conversion into text form, i.e. verbalization;
- model training;
- model inference and evaluation.
To form a verbalized input, we wrote a custom class named Verbalizer that incorporates neighborhood formation and query verbalization using KG and its corresponding textual mapping. The full code for the verbalization and a demo of the model are available in the Github repository.
Let's look at our code sections and the motivation behind them step by step:
Textual verbalization
As we treated the KGC task as a seq2seq one, we needed to convert entity ids, which are representations of nodes in Wikidata5M and many other KGs, to their textual form. For building such mapping, we used entities and relation names in English scraped from Wikipedia pages in advance:
# Relation id to text mapping
relations_path = 'demo_mappings/relation_mapping.txt'
relation_mapping = {}
with open(relations_path, 'r') as f:
for line in tqdm(f):
line = line.strip().split('\t')
id, name = line[0], line[1]
relation_mapping[id] = name# Entity id to text mapping
entities_path = "demo_mappings/entity_mapping.txt"
entity_mapping = {}
with open(entities_path, "r") as f:
for line in tqdm(f):
line = line.strip().split("\t")
id, name = line[0], line[1]
entity_mapping[id] = nameNeighborhood formation
As a KGC model should complete a triplet in both train and test dataset, we needed to form a corresponding 1-hop neighborhood for both direct and inverse queries for each of the triplets in the train and test graph. For a query (head, relation, ?), we needed to search for 1-hop neighbors associated with the head entity and, similarly, search for 1-hop neighbors associated with the tail entity for a query (tail, relation, ?):
direct_neighbors = self.base_dataset[self.base_dataset["head"] == node_id]
inverse_neighbors = self.base_dataset[self.base_dataset["tail"] == node_id]To simulate incompleteness during training and to avoid leakage of the target entity in case it persists in the test graph, we excluded the target tail entity associated with the head entity by relation, from the formed neighborhood; same for the inverse triplets:
direct_neighbors = direct_neighbors[
(direct_neighbors["tail"] != tail_id)
| (direct_neighbors["relation"] != relation_id)
]
inverse_neighbors = inverse_neighbors[
(inverse_neighbors["head"] != tail_id)
| (inverse_neighbors["relation"] != relation_id)
]Yet, some triplets from KGs yield enormously huge neighborhoods, for example, hub nodes like "human". To be able to fit a large number of neighbors into the context of the model, which is restricted to 512 tokens for most LMs including T5, we undertook the following steps:
1) In order to prioritize more significant information in the context, we ranked the neighborhood by the semantic similarity of relations from its triplets to the relation from the input triplet. Using a pre-calculated matrix of cosine similarity of textual representations of relations in KG, neighborhood sorting by semantic similarity was performed; for similarity calculation, the verbalized relations from KG were embedded by the fasttext model:
fasttext_emb = list(map(lambda x: model_en.get_sentence_vector(x), relations))
similarity_matrix = cosine_similarity(fasttext_emb)
relations = list(set(relation_mapping.values()))
direct_relation2ind = {rel: i for i, rel in enumerate(relations)}
inverse_relation2ind = {"inverse of " + rel: i for i, rel in enumerate(relations)}
relation2ind = {**direct_relation2ind, **inverse_relation2ind}
# sorting neighborhood by relation similarity
neighborhood.sort(
key=lambda x: (
self.similarity_matrix[self.relation2index[x["relation"]]][
self.relation2index[relation]
]
),
reverse=True,
)2) We limited the size of the sorted neighborhood to 512 triplets given that this is always at least as large as the size of the model's context. After verbalization, we specified a maximum length of 512 for the model tokenizer so that it can fit the verbalized neighborhood representation into the language model context:
neighborhood = neighborhood[:512]
tokenizer(verbalization, max_length=512, return_tensors='pt',
**encode_plus_kwargs)Model training & evaluation
Model setup:
- Randomly initialized T5-small with 60M parameters
- T5-small tokenizer, 30K tokens vocabulary with additional “[SEP]” token to separate query and triplets in neighborhood
- AdamW optimizer, 1e-5 learning rate, 10% dropout, and batch size 320
- Input: verbalized query and its neighborhood
- Target output: verbalized tail
- Training using teacher forcing and cross-entropy (CE) loss
- Exact Match (EM), or Hits@1, was the primary metric for picking the best model during training; it returns 1 if the generated and target sequences are the same, or 0 otherwise.
At each training stage of decoding, the model generates a probability distribution across all conceivable language tokens. When a distribution does not match the actual distribution, it is penalized using CE loss for the discrepancy between the real target token at position i and the token that was generated at step i. This process is then repeated until the end of the sequence token is generated.
This method differs significantly from distance-based approaches because it avoids the need to generate negative samples that are further from the target prediction for each training query in terms of the scoring function. Consequently, training iteration is independent of KG size.
As a common practice in the field of KG, KGC models are evaluated based on the top-k most possible answers. We carried out the following using a LM to maintain this strategy:
- k sequences with higher probabilities are chosen from the decoder, and their associated probabilities—a sum of the log probabilities of each token in the sequence—are assigned to the nodes that refer to these sequences
- nodes that weren't produced by the sampling process are given a score of infinity
- calculated Hits@k based on k most probable nodes obtained on the previous steps
GPT prompting and evaluation
ChatGPT developed by OpenAI has made a remarkable contribution to the field of Natural Language Processing (NLP). Its robust language capabilities, including context understanding and coherent response generation, have paved the way for more sophisticated and dynamic NLP models. The breakthrough in NLP obtained through the development of ChatGPT demonstrated a competitive performance for previous state-of-the-art approaches in different NLP tasks. Thus, with such a multifunctional tool available, the creation of specialized models began to seem obsolete to most engineers and researchers. Therefore, when creating new NLP-related approaches, it is always intriguing to examine whether ChatGPT can handle a more niche task better than a specialized approach.

We compared the ability of the GPT-4 recently released by OpenAI with our method, i.e. performed knowledge probing on the OpenAI’s model to test how much real-world knowledge the model contains. Also, we additionally checked whether a presence of context about adjacent nodes from KG could boost zero-shot prediction performance to verify our hypothesis on different LMs other than T5. The full code for experiments is available in the Github repository.
Zero-shot link prediction without neighborhood
System prompt for probing without neighborhood:
system_prompt = (
"You will be provided with an incomplete triplet from the Wikidata knowledge graph. "
"Your task is to complete the triplet with a tail (subject) based on the given triplet head (object) and relation. "
"Your answer should only include the tail of the triplet."
)Each user prompt contained query’s head, relation and tail request:
query = (
" ".join(wikidata_test["input_strings"][i].split(" [SEP] ")[1:2])
.replace("[SEP]", "")
.strip()
)
user_text = f"{query}. Tail: "Zero-shot link prediction with neighborhood
System prompt for probing with neighborhood:
system_prompt = (
"You will be provided with an incomplete triplet from the Wikidata knowledge graph. "
"Your task is to complete the triplet with a tail (subject) based on the given triplet head (object) and relation. "
"Your answer should only include the tail of the triplet. "
"To help you with the task you will be provided with adjacent relations and subjects. Requested subject may not be from provided adjacent subjects."
)Each user prompt contained query’s head, relation, adjacent relations separated by semicolon and tail request:
query = (
" ".join(wikidata_test["input_strings"][i].split(" [SEP] ")[1:2])
.replace("[SEP]", "")
.strip()
)
neigh = "; ".join(wikidata_test["input_strings"][i].split(" [SEP] ")[2:]).replace(
" [SEP]", ";"
)
user_text = f"Adjacent relations: {neigh}\nTriplet to complete: {query}. Tail: "Evaluation
One is unable to obtain its probabilities because the OpenAI API provides only generated text. So, unlike with the previous model, we employed a slightly different evaluation workflow. Using GPT-4, we generate up to three predictions:
params = {
"max_tokens": 10,
"temperature": 1.0,
"top_p": 1,
"n": 3,
"stream": False,
"stop": None,
}
openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_text},
],
**params,
)To avoid cases where GPT-4 generates redundant articles, punctuation or messes up with cases, we perform normalization of its answer.
And, after cleaning and normalization, if any of the k randomly chosen predictions match the target tail, we consider that model prediction a correct one.
Summary
To sum up our experiments, we compared our approach with existing baselines. In the table below we provided results for both LM-based approaches (KGT5, KEPLER) and KGE-based approaches (TransE, ComplEx) compared to our T5 models that utilize neighbors in the context and OpenAI GPT-4 probed on prompts with and without neighbors:
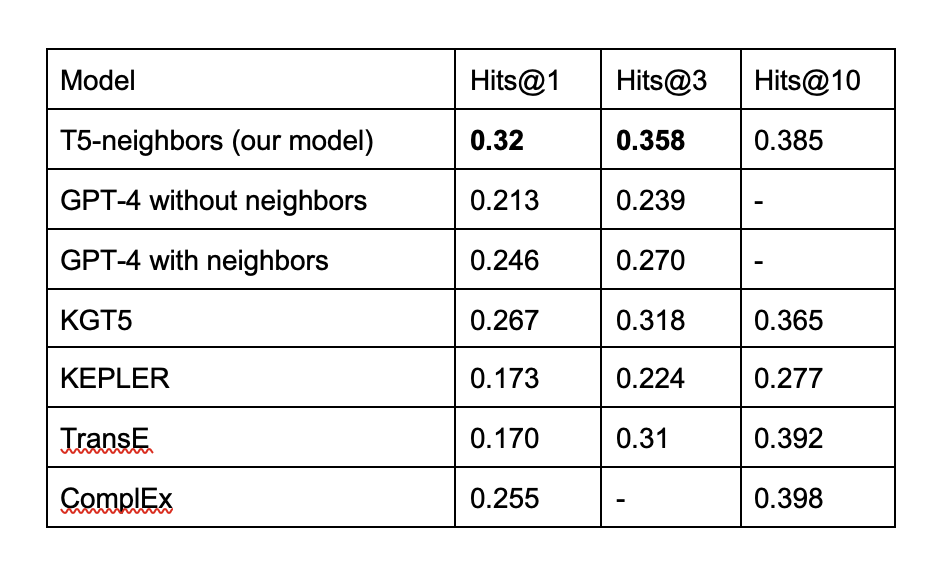
As shown in the table, the context of a generative model can improve the quality of the link prediction task through the integration of KG neighborhood information. Furthermore, this method substantially outperformed baselines on the Wikidata5M dataset.
We found out that neighborhood information is capable of enhancing the performance of the OpenAI GPT-4 when used for the KGC task without requiring any prior fine-tuning. It is still inferior to the specialized technique, though.

Thus, the use of a specialized model provides benefits both in performance and resources required for model inference in comparison with the use of OpenAI’s GPT-4.
In the HuggingFace repository 🤗 you can find our model for the KGC task, pre-trained on transductive Wikidata5M, that can be used for KGC or fine-tuning it for other downstream tasks like KGQA. Keep up with our lib updates so that you do not miss the release of new pipelines for graph data based on our recent studies!
References
[1] Wang, Meihong, Linling Qiu, and Xiaoli Wang. "A survey on knowledge graph embeddings for link prediction."
[2] Yao, Liang, Chengsheng Mao, and Yuan Luo. "KG-BERT: BERT for knowledge graph completion." arXiv preprint arXiv:1909.03193 (2019).
[3] Zha, Hanwen, Zhiyu Chen, and Xifeng Yan. "Inductive relation prediction by BERT." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 36. No. 5. 2022.
[4] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[5] Saxena, Apoorv, Adrian Kochsiek, and Rainer Gemulla. "Sequence-to-sequence knowledge graph completion and question answering." arXiv preprint arXiv:2203.10321 (2022)
[6] GPT-4. https://openai.com/gpt-4
[2] Yao, Liang, Chengsheng Mao, and Yuan Luo. "KG-BERT: BERT for knowledge graph completion." arXiv preprint arXiv:1909.03193 (2019).
[3] Zha, Hanwen, Zhiyu Chen, and Xifeng Yan. "Inductive relation prediction by BERT." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 36. No. 5. 2022.
[4] Raffel, Colin, et al. "Exploring the limits of transfer learning with a unified text-to-text transformer." The Journal of Machine Learning Research 21.1 (2020): 5485-5551.
[5] Saxena, Apoorv, Adrian Kochsiek, and Rainer Gemulla. "Sequence-to-sequence knowledge graph completion and question answering." arXiv preprint arXiv:2203.10321 (2022)
[6] GPT-4. https://openai.com/gpt-4