

ChatGPT is an AI chatbot developed by OpenAI. It gained popularity due to its ability to successfully solve various natural language processing (NLP) tasks. ChatGPT uses generative language model (LM) as a backbone architecture. The universality of ChatGPT is supported by the prompting concept. To specify the task of interest, the user provides textual instructions for the model to follow. The prompt can be a question, a statement, or any set of keywords to start interaction with the model.
Multi-hop Question Answering (MHQA) is an extension of a question-answering task where the model has to find the answer in the textual document (or a collection of documents) given a question. In multi-hop question answering, the model has to detect and logically combine the information from different parts of a document to infer the answer to the question. Such useful information is called supporting evidence. In this article, we will look at three popular MHQA datasets: HotpotQA, 2WikiMultiHopQA, and MuSiQue.
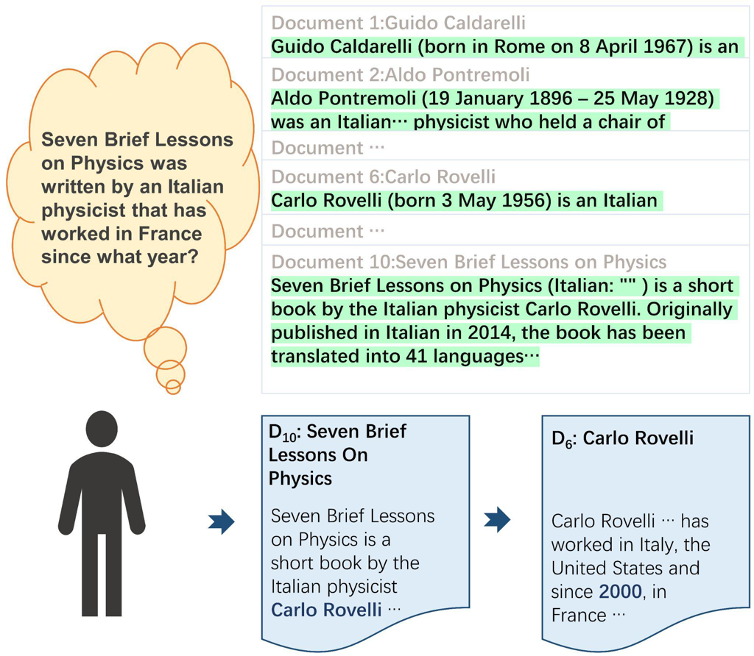
Mastering MHQA task with Transformer-based models faces the long document encoding problem due to the quadratic complexity of the attention mechanism. Also, contextual documents contain a significant amount of distracting information that increases the difficulty of the question answering task. The final challenging part of the MHQA is the multi-hop reasoning task that requires the model to logically connect the detected evidence facts to answer the question correctly.
To solve the MHQA task, we send the question concatenated with the contextual document to the language model input and predict the span from the document containing the answer. We also predict which sentences and/or paragraphs of the document represent supporting evidence. Such input/output structure works both for specific models tuned on the MHQA tasks and for ChatGPT.
Memory Augmentation for Transformers
Augmenting neural network-based models with external memory is a popular approach to storing relevant information that can improve model performance and reduce computational costs [1–4]. In this article, we will show how one can extract information relevant to the question from the contextual document, store it in the memory, and employ it to solve the MHQA task.
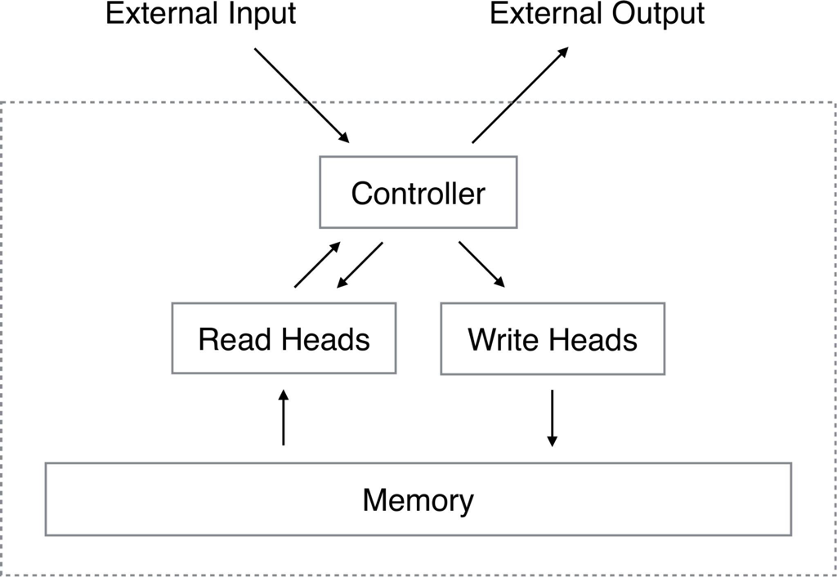
To start with, the external memory in neural networks is usually represented by a storage for information related to the model inputs and a mechanism for memory-model interaction. In early memory-augmented archictectures as Neural Turing Machines [1], the memory was a matrix operated by the dedicated read and write heads of the model.
With growing popularity of Transformers, the attention mechanism became popular solution for updating memory. Also, memory turned from a separate matrix to the part of the input sequence. For example, Extended Transformer Construction [5] combines full-self-attention and a fixed-size window attention (so-called global-local attention) to connect global input slots serving as a memory storage with local slots containing standard input sequence representations.
Our approach takes a step forward in unifying the memory and inputs processing. We serve memory as a part of Transformer input similarly to ETC and process memory-augmented sequence with a vanilla self-attention to read from memory and generate model predictions in a single forward model pass. To ease such input-memory interaction and also make memory unambiguous, we store tokens from the input in the memory.
To be precise, the memory discussed in this article is represented by a sequence of tokens originating from the contextual document. For example, consider a two-paragraph document:

Then the possible memory sequence is the following:
[romantic, film, Risa, Bramon, Garcia, starring, Sarah, Donald, Sutherland, June, born, July, 1935, Canadian, actor]
This memory sequence is placed as a part of the Transfomer input:

The memory works as a helper to the model, pointing out locations in the long document that the model should pay more attention to by simply repeating them at the beginning of the context part of the input sequence. The decision of choosing which parts of the document are notably important to solve the task correctly is made by the model itself. We use the same pre-trained encoder as in MHQA training followed by the language modeling head to measure the confidence of each contextual input slot and calculate the per-token entropy based on the output distributions. The lower the entropy value becomes, the more confident the model is about the current input slot. Thresholding the model confidence values, we can filter useful information to store in memory. In particular, we collect memory sequences of the tokens with entropy lower than the specified threshold value Ht.
The diagram below shows how the memory is generated and used in MHQA fine-tuning. First, to fit the pre-trained model input sequence length limit, the long contextual document is split into segments such that each segment concatenated with the tokenized question is within the model input length limit. Then, the segmented input is passed through the language model built from the pre-trained encoder and language modeling head to obtain per-token distributions that are used to compute entropy for each token from the context segments. Finally, tokens that satisfy the memory threshold condition form a memory sequence.
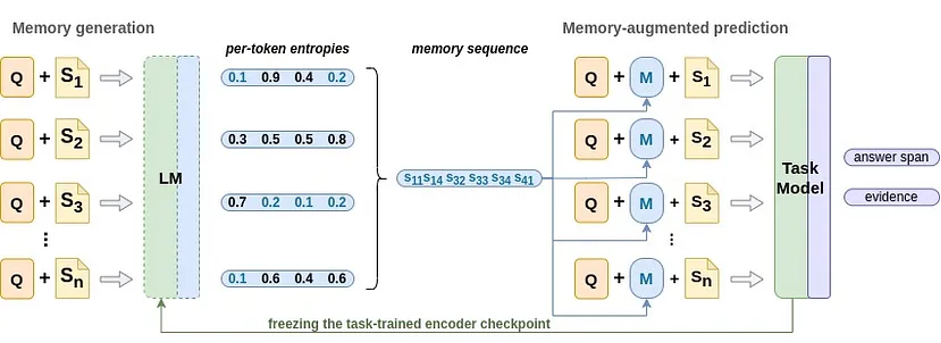
To allow both memory and the task-specific model advantage of the fine-tuning process and improve one another throughout the tuning, we regenerate the memory before each epoch using the latest version of the encoder model weights and continue training with renewed memory sequences until the end of the epoch.
Comparison of ChatGPT and a task-tuned model
The memory we obtained after finishing fine-tuning the task-specific model contains information close to the supporting evidence content and was generated automatically by the model. What if providing such information to a large language model like ChatGPT? Would it improve the model generations?
To answer this question, we evaluated the ChatGPT (gpt-3.5-turbo-0613 checkpoint of 3.5B parameters) on MHQA data augmented with memory generated by the fine-tuned task-specific model. We also tested the general skills of ChatGPT to answer the question without providing the contextual document and to perform reasoning in retrieval and fully generative settings. To test the ChatGPT reasoning skills with retrieved evidence, we presented a contextual document as a vector database over document sentences using the Langchain library. This approach reproduces the retrieval MHQA pipeline where the contextual document sentences are ranked by relevance to the question and the most relevant sentences are concatenated to the question and sent to ChatGPT with the following prompt to obtain the answer.
System:You are a world-class algorithm to answer questions in a specific format.
Human: Answer the question using the following context <context>. Question: <question>. Tips: Make sure to answer in the correct format.
The gpt-3.5-turbo-0613 checkpoint allows users to differentiate between the task instructions coming from the “system” messages and the task-related inputs given by the “human” messages content.
To assess the ChatGPT’s ability to process long textual inputs, we combined a question and a contextual document using the following prompt:
System:You are a world-class algorithm to answer questions based on the given text. Store the answer and the supporting evidence from the text in the following structure: {‘answer’: ‘answer string’, supporting evidence’: [“list of supporting evidence sentences”]
Human: Text: <context> Question: <question>
Finally, the augmentation of ChatGPT input with memory sequence was done with the following prompt:
System:You are a world-class algorithm to answer questions based on the given text and memory. Use the provided memory to detect question-related information in text. Store the answer and the supporting evidence from the text in the following structure: {‘answer’: ‘answer string’, ‘supporting evidence’: [“list of supporting evidence sentences”]}
Human: Memory: <mem> Text: <context> Question: <question>
Experimental Results
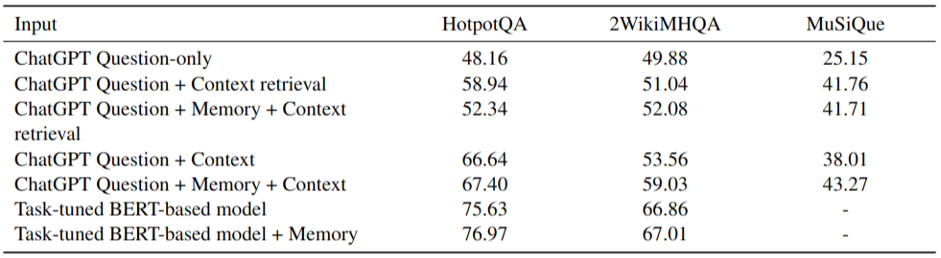
The table below presents the results of the evaluation of the ChatGPT with three types of input sequences: question-only input to assess the large language model QA ability and question plus contextual document to perform retrieval QA and generative QA. We also tested memory-augmented inputs for which we used the memory generated by our task-tuned model for each dataset.
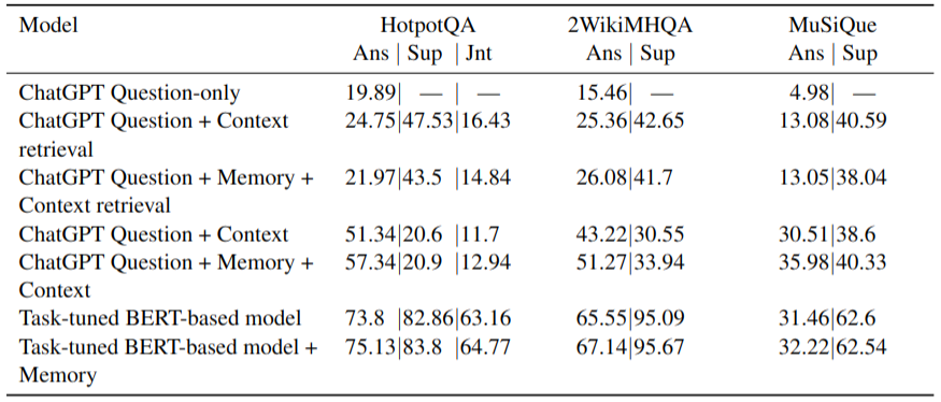
The resulting ChatGPT scores are significantly lower than the task-tuned model's performance except for the memory-augmented ChatGPT experiment on the MuSiQue dataset. This leads to the conclusion that even the smaller-sized pre-trained model that was fine-tuned on the MHQA task significantly outperforms the huge general-purpose LLM.
Now, let us look at how the memory containing the question-related information from the context affects the models' performance. First, memory addition shows almost no positive changes to the scores when using retrieval QA setup. In this case, the contextual input shrinks to the retrieved sentences. Thus, the final language model performance highly depends on the relevance of the retrieved facts. The failure of the retriever leaves no chance for the language model to find the correct answer in the context. At the same time, providing the large language model solely with the whole contextual document without adding memory strongly improves the answer prediction scores. The memory augmentation of the generative ChatGPT setup showed even more answer score improvements demonstrating that the task-relevant information helps the Transformer-based models process long documents to answer the question correctly. Comparing memory-augmented experiments with retrieved contexts and full-doc contexts, we can conclude that memory itself does not contain the correct answer to the question, but suggests the model to pay more attention to the locations in the document that are needed to solve the task.
Multi-hop question answering is an extractive task, aiming to predict the minimal document span that contains the answer. Therefore, when evaluating generative models such as ChatGPT on MHQA datasets, we need to ensure that generated answers are relevant to the contextual documents and the correct answer spans. To do that, we inspected the answer recall score which is the ratio of the number of words from the correct answer found in prediction divided by the total number of words in a correct answer. The recall scores confirmed that although LLM does not outperform the task-tuned model, firstly, the usage of the full long document context works better for LLM than retrieval, and secondly, memory augmentation improves results for both the task-tuned model and LLM.
Conclusion
Large language models such as ChatGPT gained success as out-of-the-box solutions for various natural language processing tasks with minimal effort in constructing a task description prompt or showing several in-context examples. However, the use of LLMs for complex tasks like multi-hop question answering can benefit from memory augmentation to route the model attention mechanism while performing multi-step reasoning. Also, experimental evaluations show that the model of smaller size fine-tuned on MHQA data consistently outperforms ChatGPT with and without memory augmentation. Such fine-tuned models appear to be a more effective and lightweight solution for particular tasks rather than large models with limited access.
References
[1] Alex Graves, Greg Wayne, and Ivo Danihelka. 2014. Neural Turing machines.
[2] Alex Graves, Greg Wayne, Malcolm Reynolds, Tim Harley, Ivo Danihelka, Agnieszka Grabska-Barwi ́nska, Sergio Gómez Colmenarejo, Edward Grefenstette, Tiago Ramalho, John Agapiou, Adrià Puigdomènech Badia, Karl Moritz Hermann, Yori Zwols, Georg Ostrovski, Adam Cain, Helen King, Christopher Summerfield, Phil Blunsom, Koray Kavukcuoglu, and Demis Hassabis. 2016. Hybrid computing using a neural network with dynamic external memory. Nature, 538(7626):471–476.
[3] Ankit Gupta and Jonathan Berant. 2020. Gmat: Global memory augmentation for transformers. ArXiv, abs/2006.03274.
[4] Mikhail S. Burtsev and Grigory V. Sapunov. 2020. Memory transformer. ArXiv, abs/2006.11527.
[5] Joshua Ainslie, Santiago Ontanon, Chris Alberti, Philip Pham, Anirudh Ravula Sumit Sanghai. 2020. ETC: Encoding Long and Structured Data in Transformers. ArXiv, abs/2004.08483.