
ChatGPT is an advanced language model developed by OpenAI which has amazed the world with its text generation capabilities. It is based on the GPT (Generative Pre-trained Transformer) architecture and was trained on a massive amount of text data from the internet, allowing it to generate human-like responses to a wide variety of prompts. In this article I will evaluate its ability to carry out simple NLP tasks, namely I will compare ChatGPT with traditional fine-tuned models for the KBQA task. Note, this is not a thorough research but rather an attempt to understand how ChatGPT performs in question answering compared to traditional models.
What is Knowledge Base Question Answering?
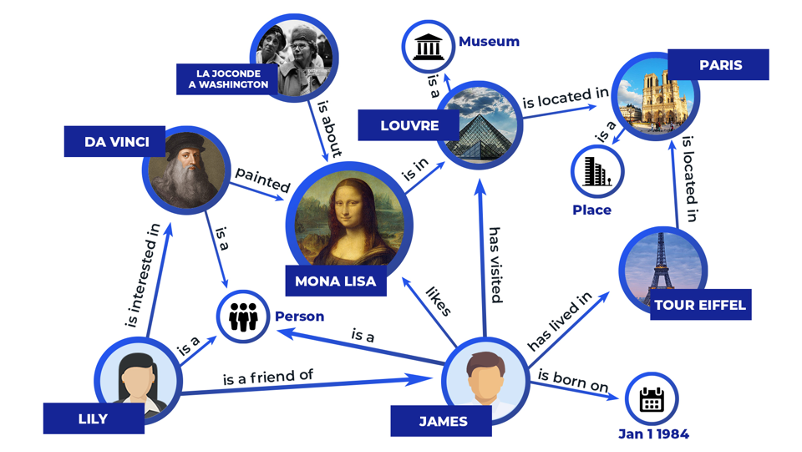
KBQA attempts to answer the question in a natural language by searching knowledge bases such as Wikidatda, DBpedia or Freebase. The information in knowledge bases is stored in a structured way and can be represented in the format <subject, relation, object>. Each triplet (also called fact) might have qualifiers which allow to indicate a more detailed information, beyond the property-value relation. For example, the wikidata page for Jim Carrey (Q40504) has a fact <“Jim Carrey”, “award received”, “Golden Globe Award”> and a further qualifier “point in time=1999”.

An answer to the question can be obtained by matching it with a relevant triplet in the knowledge base. For example, the question “What is the capital of France?” can be represented as a triple <“France'', “capital”, “?”> and the missing entity “Paris'' is the answer. KBQA’s task is to represent questions as triplets by matching the entities with their identifier in the knowledge base and perform a search to find the missing entity. The missing entities can be found by querying the knowledge base with a SPARQL query (SPARQL Protocol and RDF Query Language) which is used to query databases stored in RDF triplet format.
The applications of KBQA are diverse. It can be used in customer support systems, where users can ask questions about products or services. It also finds applications in education, where students can obtain answers to their queries from educational resources. KBQA can be employed in intelligent personal assistants, chatbots, and other interactive systems to provide users with accurate and relevant information. One advantage of KBQA over search engines is the possibility to use any knowledge base as a source, including internal knowledge bases of big enterprises.
Testing ChatGPT Knowledge
It is well known that LLMs may suffer from hallucination problems. Recently, [1], [2] conducted experiments comparing ChatGPT and other LLMs with traditional fine-tuned models in the KBQA task. The experiments illustrated that even though ChatGPT outperforms other LLMs in question answering, it still lags behind fine-tuned models on some datasets. It was also noted that ChatGPT performs badly on certain types of questions including counting, comparison, temporal, and causal questions. For the KBQA task I compare ChatGPT's ability to answer questions on LC-QuAD, a QA dataset with 5000 pairs of questions and its corresponding SPARQL query on DBpedia as knowledge source.
I did not use any prompting strategies when asking ChatGPT questions, except for asking to answer the question. Also I did not restart the session after each question and the questions were asked subsequently. Yet, some questions were asked several times, by slightly rephrasing it since ChatGPT was not returning the desired answer type. I noticed that adding extra information to the question about the answer type can enhance ChatGPT's performance in some cases (e.g numerical questions), while in others the output does not change much. Here is an example of an input to ChatGPT:

I used the ChatGPT API to collect the answers for the questions. Below is a sample code snippet showing how to query ChatGPT via API, which I adopted from their documentation page and used in my experiments. For ChatGPT call the API with gpt-3.5-turbo model. Notice that you need an API key to use ChatGPT this way and the API is not free.
import openai
openai.api_key = "YOUR-KEY-HERE"
english_prompt = "Please answer only to the following question without any further explanations unless asked so. Question:"
def call_chatgpt_api(question: str):
messages = [{"role": "user", "content": f"{english_prompt} {question}"}]
chat = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=messages
)
reply = chat.choices[0].message.content
return reply
Previous studies did not compare ChatGPT performance on LC-QuAD, therefore I randomly 50 questions from the dataset and presented them to ChatGPT. The accuracy of the answers was checked manually for the presence of the exact answer in ChatGPT’s reply. Also, some questions were discarded from the sample: 1) questions that do not have an answer in the knowledge base; 2) questions that ask to list a bunch of entities meeting a particular criteria (if the length of the gold answer is more than 5 entities). Answers from Deeppavlov KBQA were scored by calculating the exact match between the gold entities and the predicted entities. The table below represents ChatGPT’s answers categorized to three types, either as correct, incorrect or cant_answer. Here the answers were annotated as cant_answer when ChatGPT required more information to answer the question. DeepPavlov KBQA scored 54% which implies that ChatGPT’s performance is inferior to the traditional KBQA on the LC-QuAD dataset.

There is a clear trend that ChatGPT fails to correctly answer some question types which are handled well by a DeepPavlov KBQA. Below are some examples of questions where ChatGPT gave an incorrect answer with a possible reason for failure.
1. ChatGPT cannot answer questions that require knowledge of rare and not very common facts, including the domain-specific facts. These kinds of questions were mostly annotated as cant_anwer in the table above.

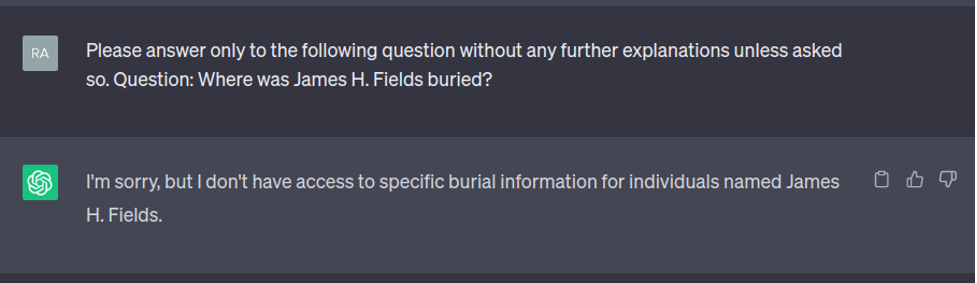
2. ChatGPT sometimes fails at multi fact questions, by either failing to make reasoning or not knowing the correct answer to one of the sub-questions.
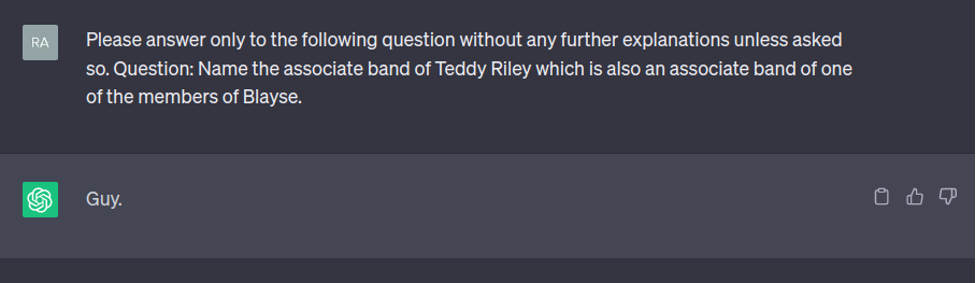
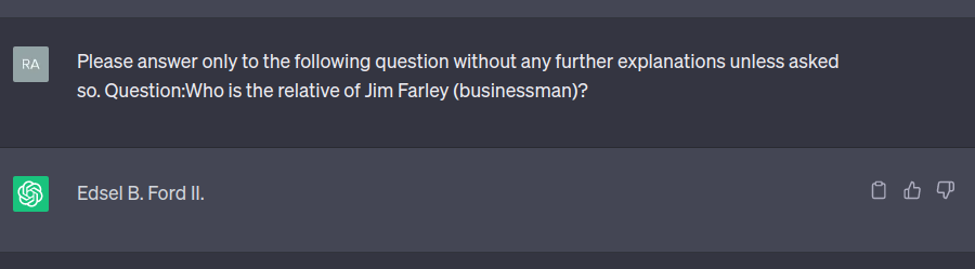
3. ChatGPT can fail even on well-known facts or simple questions, due to the lack of access to an external knowledge base. Thus ChatGPT can fabricate facts since it generates text based on statistical patterns.

How to launch KBQA in DeepPavlov?
The KBQA configuration file is located in the deeppavlov/configs/kbqa folder. The config in the main branch is for a lightweight version on Wikidata. If you are willing to use a more accurate model, please switch to feat/kbqa_research branch. The model expects a question in natural language as an input and returns a tuple (answer_string, answer_id, SPARQL_query). You can indicate what you want the model to return by changing the “return_elements” in the last component of the pipe. Possible parameters available to return are [“confidences", "answer_ids", "entities_and_rels", "queries", "triplets"].
Below is a short code snippet that allows using the pre-trained model from DeepPavlov in the feat/kbqa_researchbranch. To get started with the DeepPavlov Library, first you need to install it by running the following command.
pip install deeppavlov==1.0.1
from deeppavlov import build_model, configs
model = build_model('kbqa_lcquad', download=True, install=True)
model(["Who is the director of Forrest Gump?”])
# ('Robert Zemeckis', ['Robert_Zemeckis'], ['SELECT ?uri WHERE { dbr:Forrest_Gump dbp:director ?uri. }'])Then, after installing the necessary config, you can start using the DeepPavlov Library right away. There is also a Google Colab notebook available to play around with KBQA here. For more information on how to use or train KBQA using DeepPavlov, please refer to the documentation. The current version of KBQA in the library is based on [3].
Conclusion
This article was a short comparison of ChatGPT with traditional fine-tuned models in the KBQA task. For the purposes of comparison, KBQA model in the DeepPavlov library was chosen. It was demonstrated that ChatGPT still lags behind traditional models in the question answering task, mostly due to the inability to answer not common facts or hallucination problems. All the code to lauch KBQA is available in the Colab.
Reference:
1. Evaluation of ChatGPT as a Question Answering System for Answering Complex Questions [https://arxiv.org/pdf/2303.07992.pdf]
2. ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots [https://arxiv.org/pdf/2302.06466.pdf]
3. SPARQL query generation for complex question answering with BERT and BiLSTM model [https://www.dialog-21.ru/media/5088/evseevdaplusarkhipov-myu-048.pdf]