

In real-world tasks, machine learning engineers often have to solve multiple specific tasks at once rather than just one. To do this, they use BERT-like models that are pre-trained on a large volume of data and then fine-tuned for each of the specific tasks. So, they are single-task models.
However, hosting many single-task models can be GPU and RAM memory-intensive, leading to high costs.
To address this, we implemented Multi-Task Learning(MTL) in the DeepPavlov library. You can find the implementation notebook here.
What is DeepPavlov?
DeepPavlov Library is a conversational open-source library for Natural Language Processing (NLP) and Multi-skill AI Assistant development. This library contains many essential state-of-the-art NLP models.
You can look at our previous article to see an introduction to DeepPavlov.
This article describes the Multi-Task Learning (MTL) in the DeepPavlov library. These models have been supported in the library since the release 1.1.1. This release is based on PyTorch and leverages Transformer and Datasets packages from HuggingFace to train various transformer-based models on hundreds of datasets.
What is the multi-task model?
The multi-task machine learning model is a model that can simultaneously handle and perform multiple distinct tasks. It obtains the common features using the backbone model and then leverages these features using task-specific layers.
Let’s illustrate this with the example of a human trying to guess their companion’s mood, personality, and occupation:
Imagine you meet a new person at a social gathering, and you want to understand more about them beyond the initial introduction. As a human, you’ve learned from past experiences that certain observable cues can provide hints about a person’s mood, personality, and occupation. These cues can be analogous to features used in machine learning models.
1. Mood Recognition Task: To assess their mood, you might look at their facial expressions, body language, and tone of voice. A smile might suggest a positive mood, while a furrowed brow might indicate stress or concern.
2. Personality Inference Task: As you engage in conversation, you might pay attention to their communication style, topics of interest, and social interactions. An outgoing and talkative demeanor might indicate an extroverted personality, while someone who prefers listening might lean towards introversion.
3. Occupation Identification Task: You may observe their attire, accessories, and any work-related discussions. A uniform or specific clothing associated with a profession might hint at their occupation.
Doing these predictions, you’d learn to extract relevant features for each subtask and utilize shared information across all tasks. For example, positive facial expressions might be indicative of both a positive mood and an outgoing personality.
Now, let’s draw the parallel to a multi-task model:
Just like humans can leverage knowledge from past interactions with various people to improve their ability to make guesses about new companions, multi-task models learn to leverage information from multiple tasks to improve their overall performance and generalization capabilities.
Therefore, multi-task learning is not only computationally cheaper than single-task learning. It can also achieve the knowledge transfer effect: the effect when the knowledge acquired in one task enhances the performance on other tasks.
Multi-task architecture in DeepPavlov
Our MTL model is based on the AutoModel class from HuggingFace, which allows the use of different transformer-based architectures as a backbone. For a reference, see the HuggingFace list of supported models.
In two words, this model uses a task-specific linear layer for every task on top of the output. It’s as simple as that.
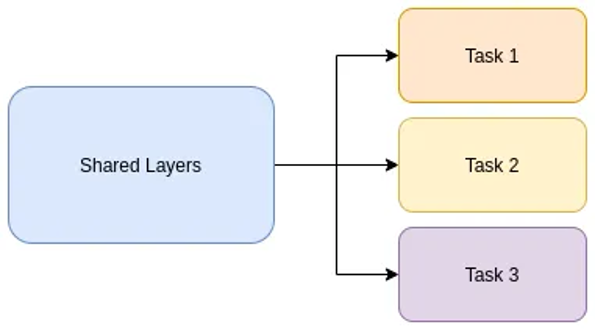
The multi-task model in our setting requires almost no additional parameters and computational overhead, apart from the linear layers, so its simplicity singles it out.
Our MTL implementation supports:
- text classification
- text regression (e.g. STS-B)
- sequence labeling task (e.g NER, POS)
- multiple choice task (e.g. COPA)
It can work with sentences as well as with sentence pairs.
For the GLUE task set, multi-task models on average perform better than single-task ones (see our docs for details). You can also read more about such models in our paper.
Below, you will see how you can invoke the multi-task DeepPavlov models.
Inference of the multi-task config
Here is an example of code for inference of these models. We show how this model works for all supported types of tasks. You can also find that example in this notebook.
First of all, we need to install the DeepPavlov of the appropriate version.
First of all, we need to install the DeepPavlov of the appropriate version.
# Install the right version
!pip install deeppavlov==1.1.1
from deeppavlov import build_model, configs
model = build_model('multitask_example', download=True, install=True)
# If you use your config from scratch, it should look like
# model = build_model('path/to/your/config.json')
tasks =['cola', 'rte', 'stsb', 'copa', 'conll']
# the same order as config
x=dict()
for task in tasks: # Buillding input
if task=='rte': # Sentence pair classification/regression
# Example can be a tuple
x[task]=[('pair 1 phrase 1', 'pair 1 phrase 2'),
('pair 2 phrase 1', 'pair 2 phrase 2')]
elif task=='cola': # Single sentence classification/regression
# Example can be a string
x[task]=['phrase1']
elif task=='conll': # NER
# For NER, examples are strings
x[task]=['first second'] # NER
elif task=='stsb': # Single sentence regression.
#Examples for any task can be empty, like in that case
x[task]=[]
elif task=='copa':
x[task]=[('context in pair 1', ['choice 1 in pair 1', 'choice 2 in pair 1']),
('context in pair 2', ['choice 1 in pair 2', 'choice 2 in pair 2'])]
# Illustrating multiple choice task
else:
x[task]=['test phrase']
list_of_x = [x[task] for task in tasks]
list_of_y = [[] for _ in tasks]
args = list_of_x + list_of_y
outputs=model(*args)Below, we will explain in detail how can you train the multi-task model for your own tasks. To do so, you firstly need to make the config.
We will show you making the config which combines the sentence pair classification task (RTE) with the sequence labeling task (CONLL) and the multiple choice task (COPA). We have retained only these tasks from the aforementioned example to streamline the config. You can download this streamlined config here.
We will show you making the config which combines the sentence pair classification task (RTE) with the sequence labeling task (CONLL) and the multiple choice task (COPA). We have retained only these tasks from the aforementioned example to streamline the config. You can download this streamlined config here.
Making the multi-task config
Dataset reader
Before working with data, we need to read it. That is why the component dataset_reader is needed in the DeepPavlov library.
To implement a dataset_reader component, we use the multitask_reader class. This class must have the parameter tasks, which is a dictionary {task name: parameters for the task}. The order of the tasks in this dictionary must be exactly the same as at the later stages of the config.
Any parameter for any task, if it does not exist in that dictionary, is drawn from another parameter called task_defaults.task_defaults contains the default dictionary for any task (the dictionary can also be empty).
The dataset_reader, path, train, validation, and test fields must exist for all tasks — either as default fields or as fields that are explicitly given in the dictionary.
For example:
To implement a dataset_reader component, we use the multitask_reader class. This class must have the parameter tasks, which is a dictionary {task name: parameters for the task}. The order of the tasks in this dictionary must be exactly the same as at the later stages of the config.
Any parameter for any task, if it does not exist in that dictionary, is drawn from another parameter called task_defaults.task_defaults contains the default dictionary for any task (the dictionary can also be empty).
The dataset_reader, path, train, validation, and test fields must exist for all tasks — either as default fields or as fields that are explicitly given in the dictionary.
For example:
{
"dataset_reader": {
"class_name": "multitask_reader",
"task_defaults": {
"class_name": "huggingface_dataset_reader",
"path": "glue",
"train": "train",
"valid": "validation",
"test": "test"
},
"tasks": {
"rte": {"name": "rte"},
"copa": {
"path": "super_glue",
"name": "copa"
},
"conll": {
"class_name": "conll2003_reader",
"use_task_defaults": false,
"data_path": "{DOWNLOADS_PATH}/conll2003/",
"dataset_name": "conll2003",
"provide_pos": false
}
}
},You can also use your own data here, like in any DeepPavlov config.
Dataset iterator
To implement a dataset_iterator component, we use the multitask_iterator class. In this class, we also pass the dictionary tasks, which contain an iterator class name and parameters (if they are set) for all tasks analogously to the multitask_reader.
We also set the number of gradient accumulation steps, training epochs, and batch size in the same class (these parameters need to be also in the trainer).
We also pass into the multitask_iterator sampling mode, which defines for every task a probability that the samples will be drawn from its set of samples. We support uniform sampling (the same sampling probability for all tasks), plain sampling (sampling probability is proportional to the sample number), and annealed sampling (as in this paper).
Note that dataset_reader and dataset_iterator are not required in the inference-only setting.
We also set the number of gradient accumulation steps, training epochs, and batch size in the same class (these parameters need to be also in the trainer).
We also pass into the multitask_iterator sampling mode, which defines for every task a probability that the samples will be drawn from its set of samples. We support uniform sampling (the same sampling probability for all tasks), plain sampling (sampling probability is proportional to the sample number), and annealed sampling (as in this paper).
Note that dataset_reader and dataset_iterator are not required in the inference-only setting.
"dataset_iterator": {
"class_name": "multitask_iterator",
"num_train_epochs": "{NUM_TRAIN_EPOCHS}",
"gradient_accumulation_steps": "{GRADIENT_ACC_STEPS}",
"seed": 42,
"task_defaults": {
"class_name": "huggingface_dataset_iterator",
"label": "label",
"use_label_name": false,
"seed": 42
},
"tasks": {
"rte": {
"features": ["sentence1", "sentence2"]
},
"copa": {
"features": ["contexts", "choices"]
},
"conll": {
"class_name": "basic_classification_iterator",
"seed": 42,
"use_task_defaults": false
}
}
},Chainer
The chainer component can utilize elements for every task independently from the other task’s elements.
However, to streamline the multi-task preprocessing, we have introduced the optional multitask_pipeline_preprocessorclass. For this class, you should set the vocab_file for the tokenizer and either the default preprocessor class name or the list of preprocessor names (not the ones used in configs, but the ones defined in the library). The user can also set whether to make the examples lower-cased and whether to print the first example. Printing the first example can assist with debugging, as it helps to rule out possible problems with data.
However, to streamline the multi-task preprocessing, we have introduced the optional multitask_pipeline_preprocessorclass. For this class, you should set the vocab_file for the tokenizer and either the default preprocessor class name or the list of preprocessor names (not the ones used in configs, but the ones defined in the library). The user can also set whether to make the examples lower-cased and whether to print the first example. Printing the first example can assist with debugging, as it helps to rule out possible problems with data.
"chainer": {
"in": ["x_rte", "x_copa", "x_conll"],
"in_y": ["y_rte", "y_copa", "y_conll"],
"pipe": [
{
"class_name": "multitask_pipeline_preprocessor",
"possible_keys_to_extract": [0, 1],
"preprocessors": [
"TorchTransformersPreprocessor",
"TorchTransformersMultiplechoicePreprocessor",
"TorchTransformersNerPreprocessor"
],
"do_lower_case": true,
"n_task": 3,
"vocab_file": "{BACKBONE}",
"max_seq_length": 200,
"max_subword_length": 15,
"token_masking_prob": 0.0,
"return_features": true,
"in": ["x_rte", "x_copa", "x_conll"],
"out": [
"bert_features_rte",
"bert_features_copa",
"bert_features_conll"
]
},
{
"id": "vocab_conll",
"class_name": "simple_vocab",
"unk_token": ["O"],
"pad_with_zeros": true,
"save_path": "{MODELS_PATH}/tag.dict",
"load_path": "{MODELS_PATH}/tag.dict",
"fit_on": ["y_conll"],
"in": ["y_conll"],
"out": ["y_ids_conll"]
},Multitask_transformer
To define the multi-task model, we use the multitask_transformer class. The backbone model for multi-task training is defined in this class; we advise using the same one as the one used for the tokenization in the previous components.
In this class, you should give as a tasks parameter a dictionary that has exactly the same order of tasks as in the reader, iterator, and in_x and in_y components in the chainer.
For every task, the options and the task_type parameters need to be set.
You give “in” (bert_features, the same order as tasks have) and “in_y” (y for every task, also the same order) and you obtain probabilities if return_probas is True, or label indexes otherwise. This does not apply to the regression and NER tasks (sts-b and conll in config).
In this class, you should give as a tasks parameter a dictionary that has exactly the same order of tasks as in the reader, iterator, and in_x and in_y components in the chainer.
For every task, the options and the task_type parameters need to be set.
You give “in” (bert_features, the same order as tasks have) and “in_y” (y for every task, also the same order) and you obtain probabilities if return_probas is True, or label indexes otherwise. This does not apply to the regression and NER tasks (sts-b and conll in config).
{
"id": "multitask_transformer",
"class_name": "multitask_transformer",
"optimizer_parameters": {"lr": 2e-5},
"gradient_accumulation_steps": "{GRADIENT_ACC_STEPS}",
"learning_rate_drop_patience": 2,
"learning_rate_drop_div": 2.0,
"return_probas": true,
"backbone_model": "{BACKBONE}",
"save_path": "{MODEL_PATH}",
"load_path": "{MODEL_PATH}",
"tasks": {
"rte": {
"type": "classification",
"options": 2
},
"copa": {
"type": "multiple_choice",
"options": 2
},
"conll": {
"type": "sequence_labeling",
"options": "#vocab_conll.len"
}
},
"in": [
"bert_features_rte",
"bert_features_copa",
"bert_features_conll"
],
"in_y": ["y_rte", "y_copa", "y_ids_conll"],
"out": [
"y_rte_pred_probas",
"y_copa_pred_probas",
"y_conll_pred_ids"
]
},Multi-task metrics
After the multitask_transformer, all other components are the same as in the single-task setting:
{
"in": ["y_rte_pred_probas"],
"out": ["y_rte_pred_ids"],
"class_name": "proba2labels",
"max_proba": true
},
{
"in": ["y_copa_pred_probas"],
"out": ["y_copa_pred_ids"],
"class_name": "proba2labels",
"max_proba": true
},
{
"in": ["y_conll_pred_ids"],
"out": ["y_conll_pred_labels"],
"ref": "vocab_conll"
}
],
"out": ["y_rte_pred_ids", "y_copa_pred_ids", "y_conll_pred_labels"]
},However, metrics multitask_accuracy, multitask_f1_macro, and multitask_f1_weighted are new. Each of these metrics is computed by calculating the corresponding metrics (accuracy, f1-macro, and f1-weighted) for all tasks separately and then averaging the metrics by task, respectively. As in any DeepPavlov library config, the early stopping is performed for the first metric in the metric list. In this config, it is a multitask accuracy, which is calculated as a mean value of all accuracies by task, unweighted.
"train": {
"epochs": "{NUM_TRAIN_EPOCHS}",
"batch_size": 32,
"metrics": [
{
"name": "multitask_accuracy",
"inputs": ["y_rte", "y_copa", "y_rte_pred_ids", "y_copa_pred_ids"]
},
{
"name": "ner_f1",
"inputs": ["y_conll", "y_conll_pred_labels"]
},
{
"name": "ner_token_f1",
"inputs": ["y_conll", "y_conll_pred_labels"]
},
{
"name": "accuracy",
"alias": "accuracy_rte",
"inputs": ["y_rte", "y_rte_pred_ids"]
},
{
"name": "accuracy",
"alias": "accuracy_copa",
"inputs": ["y_copa", "y_copa_pred_ids"]
}
],
"validation_patience": 3,
"log_every_n_epochs": 1,
"show_examples": false,
"evaluation_targets": ["valid"],
"class_name": "torch_trainer",
"pytest_max_batches": 2
},
"metadata": {
"variables": {
"ROOT_PATH": "~/.deeppavlov",
"MODELS_PATH": "{ROOT_PATH}/models/multitask_example",
"DOWNLOADS_PATH": "{ROOT_PATH}/downloads",
"BACKBONE": "distilbert-base-uncased",
"MODEL_PATH": "{MODELS_PATH}/{BACKBONE}_3task",
"NUM_TRAIN_EPOCHS": 5,
"GRADIENT_ACC_STEPS": 1
}
}
}Training the model
To train the multitask model described above (mtl_3task.json), you need to run one command:
python -m deeppavlov train mtl_3task.json{$te}
Conclusion
The multi-task model implemented in the DeepPavlov library enables a significant reduction in the computational resources usage, without compromising the model quality. We hope this was helpful and that you’ll be eager to use the DeepPavlov library for your own Multi-Task Learning use cases.
You can read more about us on our official blog and about Multi-Task Learning in DeepPavlov in our manual. Visit us on the GitHub page. And don’t forget that DeepPavlov has a dedicated forum where any questions concerning the framework and the models are welcome. We appreciate your feedback, let us know what you like and what you dislike about the DeepPavlov library.
You can read more about us on our official blog and about Multi-Task Learning in DeepPavlov in our manual. Visit us on the GitHub page. And don’t forget that DeepPavlov has a dedicated forum where any questions concerning the framework and the models are welcome. We appreciate your feedback, let us know what you like and what you dislike about the DeepPavlov library.