

Welcome to our third tutorial, where we will walk you through the process of building your own personal assistant using DeepPavlov Dream. In our previous tutorials, we:
1) developed a bot capable of engaging in conversations about movies and answering factoid questions utilizing existing Dream components without any modifications;
2) created a generative bot with an enthusiastic and adventurous persona modifying the existing Dream persona distribution.
Now, in this tutorial, we will look at an experimental Dream Reasoning distribution that uses OpenAI ChatGPT to think of actions required to handle user requests and to select the appropriate API to complete them. We will dive into the work pipeline of this distribution and, after that, we will learn how to add new APIs to it.
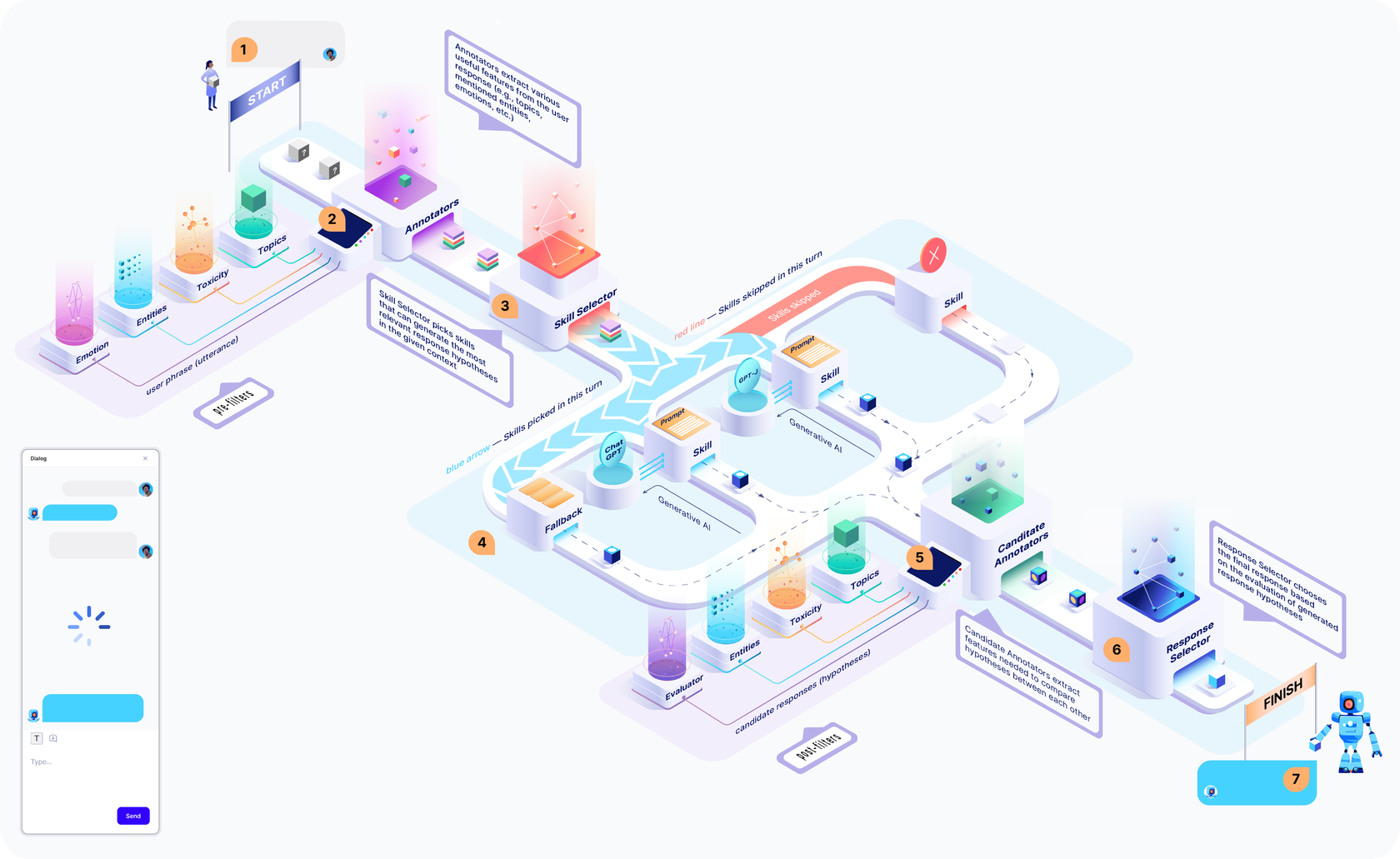
Dream architecture
Let’s take a closer look at the parts that make up Dream before we start developing our bot. As you can see in the figure below, our pipeline architecture consists of the following components:
- Annotators perform NLU preprocessing on an utterance;
- Skill Selector chooses the relevant skills that can provide the next bot’s response;
- Skills are in charge of generating candidate responses;
- Candidate Annotators perform NLU postprocessing on the candidate responses;
- Response Selector selects the most suitable response from the generated candidates;
- Response Annotators carry out post-processing of the bot’s response;
- Dialogue State stores all the information about the current dialog including all annotations and meta-data.
About Dream Reasoning Distribution
Dream Reasoning is a new addition to the Dream. It uses the power of LLMs to identify actions and necessary tools for handling user requests. While its current capabilities are limited to single-step tasks, we have ambitious plans for its future development. We aim to enhance its functionality, enabling it to handle complex tasks that require multiple steps and to reflect on its own performance.
Dream Reasoning consists of the following components:
Annotators:
Skills:
Dream Reasoning consists of the following components:
Annotators:
- Sentseg – allows us to handle long and complex user’s utterances by splitting them into sentences and recovering punctuation if it is missing;
- Combined Classification — annotator for topic classification, dialog acts classification, sentiment, toxicity, emotion, factoid classification;
Skills:
- Dummy Skill — a fallback skill with multiple non-toxic candidate responses in case other skills fail to provide a response;
- Reasoning Skill – does all the work. See the scheme below.
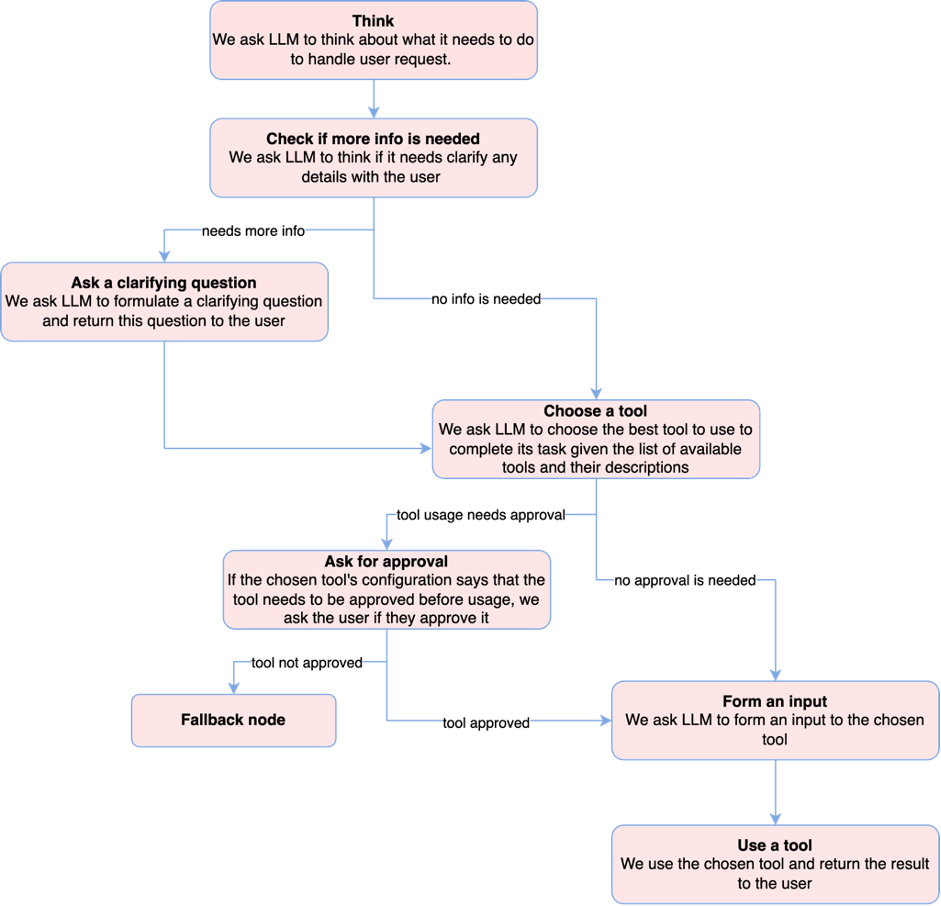
Candidate Annotators:
And here is the list of available tools:
- Combined Classification — annotator for topic classification, dialog acts classification, sentiment, toxicity, emotion, factoid classification;
- Sentence Ranker – ranges the candidate-responses based on their semantic similarity to the user’s request.
And here is the list of available tools:
- Generative LM – uses language models to generate responses;
- Google API – utilizes Google to respond to a wide variety of questions;
- News API – provides trending news;
- Weather API – provides current weather information for a given location;
- WolframAlpha API – performs calculations and does math.
Let’s create our bot!
Install DeepPavlov Dreamtools:
pip install git+https://github.com/deeppavlov/deeppavlov_dreamtools.gitClone Dream repository:
git clone https://github.com/deeppavlov/dream.gitGo to cloned repository:
cd dreamCreate a distribution from Dream Reasoning
dreamtools clone dist dream_tools
--template dream_reasoning
--display-name "Dream Tools"
--author deepypavlova@email.org
--description "This is a copy of Dream Reasoning with arxiv API added."
--overwrite
dreamtools add component components/sdjkfhaliueytu34ktkrlg.yml
--dist dream_toolsNow let’s add a new tool in our distribution – arxiv API. Go to skills/dff_reasoning_skill/scenario/api_responses and create file arxiv_api.py:
import arxiv
from df_engine.core import Context, Actor
from scenario.utils import compose_input_for_API
def arxiv_api_response(ctx: Context, actor: Actor, *args, **kwargs) -> str:
api_input = compose_input_for_API(ctx, actor)
search = arxiv.Search(
query = api_input,
max_results = 3,
sort_by = arxiv.SortCriterion.SubmittedDate
)
response = ""
for result in search.results():
response += f"TITLE: {result.title}.\nSUMMARY: {result.summary}\LINK: {result}\n\n"
return responseIn skills/dff_reasoning_skill/scenario/response.py, add
from scenario.api_responses.arxiv_api import arxiv_api_response
assert arxiv_api_responseIn skills/dff_reasoning_skill/api_configs, create arxiv_api.json:
{
"arxiv_api": {
"display_name": "arxiv API",
"description": "arxiv API can search for latest articles on requested keyword.",
"keys": [],
"needs_approval": "False",
"timeout": 30,
"input_template": "Return only the keyword that is needed to be searched for. E.g., 'ChatGPT', 'dialog systems'."
}
}In skills/dff_reasoning_skill/requirements.txt, add
arxiv==1.4.7In assistant_dists/dream_tools/docker-compose.override.yml add arxiv_api.json to API_CONFIGS fields:
dff-reasoning-skill:
env_file:
- .env
- .env_secret
build:
args:
SERVICE_PORT: 8169
SERVICE_NAME: dff_reasoning_skill
API_CONFIGS: generative_lm.json,google_api.json,news_api.json,weather_api.json,wolframalpha_api.json,arxiv_api.json
GENERATIVE_SERVICE_URL: http://openai-api-chatgpt:8145/respond
GENERATIVE_SERVICE_CONFIG: openai-chatgpt.json
GENERATIVE_TIMEOUT: 120
N_UTTERANCES_CONTEXT: 1
ENVVARS_TO_SEND: OPENAI_API_KEY,GOOGLE_CSE_ID,GOOGLE_API_KEY,OPENWEATHERMAP_API_KEY,NEWS_API_KEY,WOLFRAMALPHA_APP_ID
context: .
dockerfile: skills/dff_reasoning_skill/Dockerfile
command: gunicorn --workers=1 server:app -b 0.0.0.0:8169 --reload
environment:
SERVICE_PORT: 8169
SERVICE_NAME: dff_reasoning_skill
API_CONFIGS: generative_lm.json,google_api.json,news_api.json,weather_api.json,wolframalpha_api.json,arxiv_api.json
GENERATIVE_SERVICE_URL: http://openai-api-chatgpt:8145/respond
GENERATIVE_SERVICE_CONFIG: openai-chatgpt.json
GENERATIVE_TIMEOUT: 120
N_UTTERANCES_CONTEXT: 1
ENVVARS_TO_SEND: OPENAI_API_KEY,GOOGLE_CSE_ID,GOOGLE_API_KEY,OPENWEATHERMAP_API_KEY,NEWS_API_KEY,WOLFRAMALPHA_APP_ID
deploy:
resources:
limits:
memory: 1.5G
reservations:
memory: 1.5G
In dream directory, create file .env_secret and add your OpenAI API key there:
OPENAI_API_KEY=If you want to test your distribution with existing APIs (not only arxiv API), you also need to add keys for them. Here is the guide on how to get them. However, if you do not provide certain keys, the skill will still function without the APIs that require those missing keys.
GOOGLE_CSE_ID=
GOOGLE_API_KEY=
OPENWEATHERMAP_API_KEY=
NEWS_API_KEY=
WOLFRAMALPHA_APP_ID=
In assistant_dists/dream_tools, create proxy.yml:
services:
sentseg:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8011
- PORT=8011
combined-classification:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8087
- PORT=8087
sentence-ranker:
command: [ "nginx", "-g", "daemon off;" ]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8128
- PORT=8128
version: '3.7'Build your distribution:
docker-compose -f docker-compose.yml -f
assistant_dists/dream_tools/docker-compose.override.yml -f
assistant_dists/dream_tools/proxy.yml up --buildPlease note that in the command, we also utilize the assistant_dists/dream_adventurer_openai_prompted/proxy.yml configuration. This configuration enables you to conserve your local resources by employing proxied copies of certain services hosted by DeepPavlov.
In a separate terminal tab, run:
docker-compose exec agent python -m
deeppavlov_agent.run agent.debug=false agent.channel=cmd
agent.pipeline_config=assistant_dists/dream_tools/pipeline_conf.jsonEnter your username and have a chat with Dream!
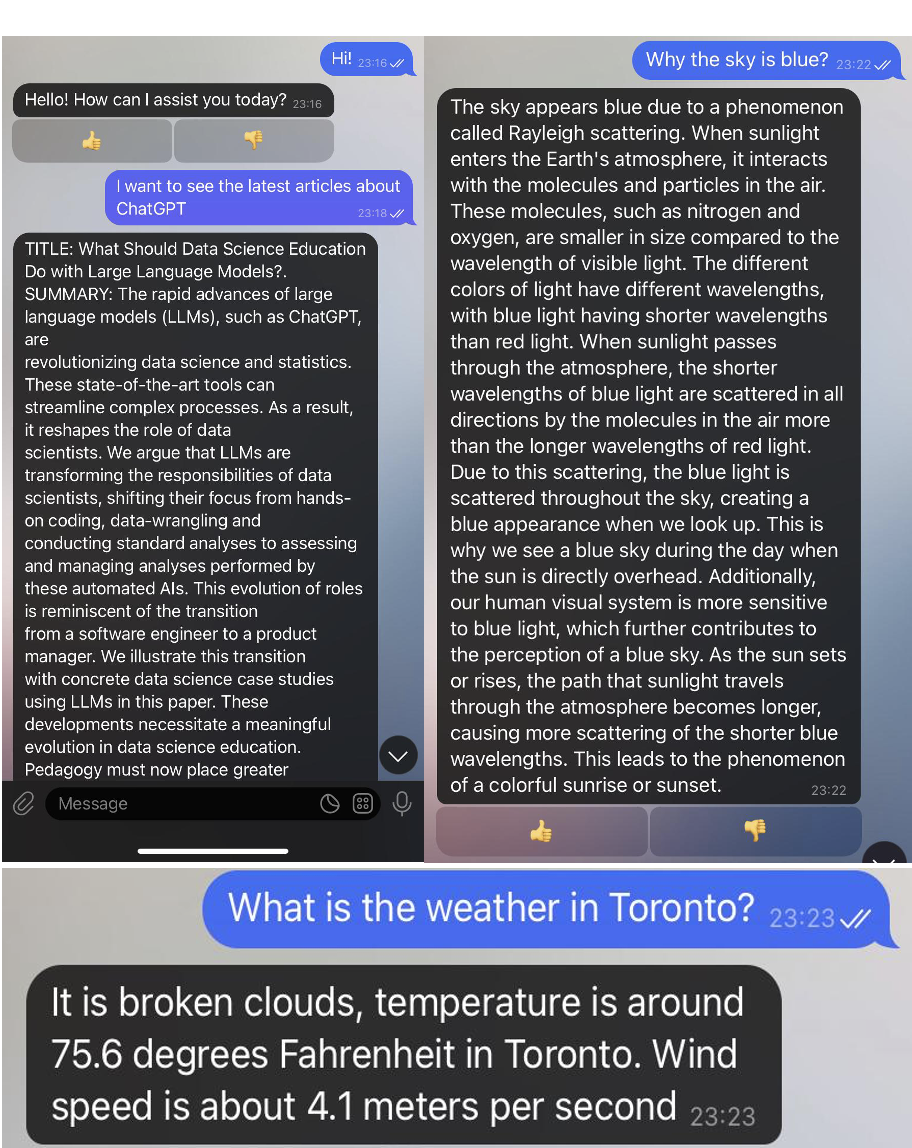
Useful links
- Dream Website
- Dream on GitHub
- DeepPavlov Discord
- Dream FAQ
- Creating Assistants with DeepPavlov Dream. Part 1: Distribution from Existing Components
- Creating Assistants with DeepPavlov Dream. Part 2: Customizing Prompt-based Distribution
- Creating Assistants with DeepPavlov Dream. Part 4: Document-based Question Answering with LLMs
- Building Generative AI Assistants with DeepPavlov Dream
- Prompting For Response Generation: Which LLM to Choose to Build Your Own Chatbot