

This is our fourth tutorial where we will guide you through the process of creating your very own assistant using DeepPavlov Dream. In our previous tutorials, we developed a bot capable of engaging in conversations about movies and answering factoid questions and a generative bot with an enthusiastic and adventurous persona. We accomplished this by utilizing existing Dream components with only minor modifications, i.e., altering the prompt and switching from one generative model to another. We have also demonstrated how to use Dream distribution that generates responses by making calls to various APIs and shown how to add a new API of your choice into it.
In this tutorial, we will create a dialog system capable of answering questions over one or several long documents with the use of ChatGPT or other large language model. We will once again utilize the existing components with only slight alterations.
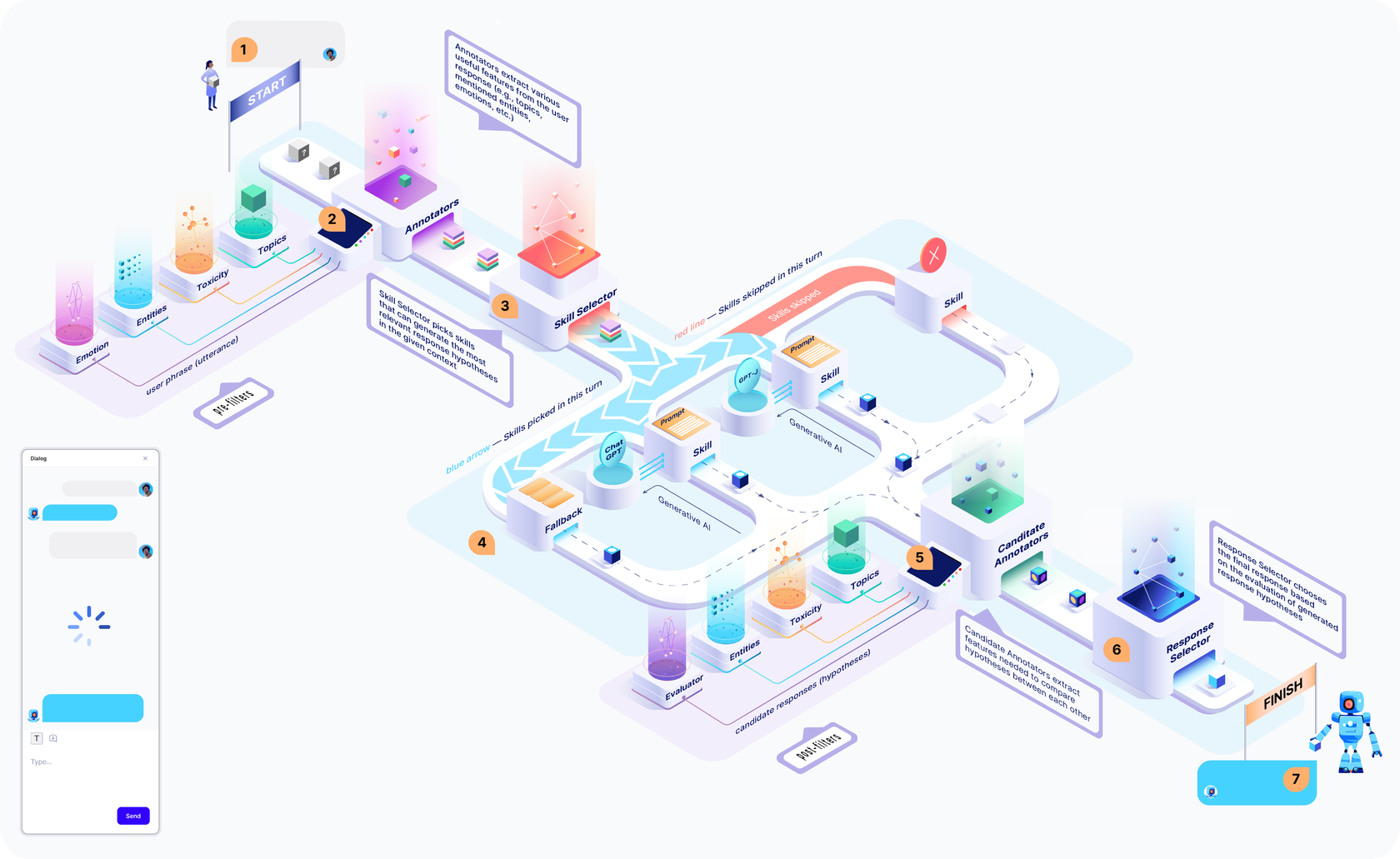
Dream architecture
Let’s take a closer look at the parts that make up Dream before we start developing our bot. As you can see in the figure below, our pipeline architecture consists of the following components:
- Annotators perform NLU preprocessing on an utterance;
- Skill Selector chooses the relevant skills that can provide the next bot’s response;
- Skills are in charge of generating candidate responses;
- Candidate Annotators perform NLU postprocessing on the candidate responses;
- Response Selector selects the most suitable response from the generated candidates;
- Response Annotators carry out post-processing of the bot’s response;
- Dialogue State stores all the information about the current dialog including all annotations and meta-data.
About Document-based LLM QA Distribution
Document-based LLM QA is a distribution of Dream designed to answer questions about the content of one or several documents supplied by the user. This distribution uses TF-IDF vectorization and cosine similarity to detect parts of documents most relevant to the user’s question. N most relevant parts, alongside with an instruction and the dialog context are then passed on to ChatGPT as a prompt. Here is the instruction:
You are a question answering system that can answer the user’s questions based on the text they provide. If user asks a question, answer based on Text that contains some information about the subject.
If necessary, structure your answer as bullet points. You may also present information in tables.
If Text does not contain the answer, apologize and say that you cannot answer based on the given text.
Only answer the question asked, do not include additional information. Do not provide sources.
Text may contain unrelated information. If user does not ask a question, disregard the Text and just talk to them as if you are a friendly question-answering system designed to help them understand long documents.
Text:
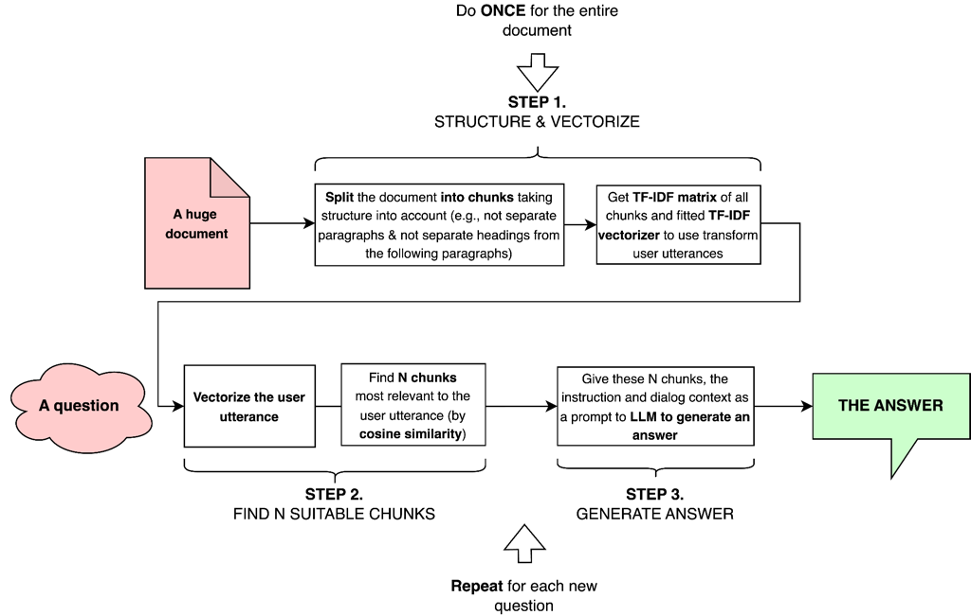
When given as an input to LLM, this prompt is followed by N most relevant excerpts from the document(s) provided by the user. These excerpts are defined as those with the highest cosine similarity between the user request’s TF-IDF vector and the excerpt’s TF-IDF vector.
By extracting most relevant chunks and inserting only these chunks into prompt instead of the entire text, the distribution is capable of answering questions over documents that are much longer than the LLM’s context length.
By extracting most relevant chunks and inserting only these chunks into prompt instead of the entire text, the distribution is capable of answering questions over documents that are much longer than the LLM’s context length.
Document-based LLM QA distribution consists of the following components:
Annotators:
Skills:
Candidate Annotators:
Annotators:
- Sentseg – allows us to handle long and complex user’s utterances by splitting them into sentences and recovering punctuation if it is missing;
- Document Retriever (train_and_upload_model endpoint) – when the documents are received, this endpoint converts them to txt format if necessary and splits into chunks of ~100 words. Chunks are then transformed into a term-document matrix; the resulting vectors and the vectorizer are saved for further use. This step is performed only once;
- Document Retriever (return_candidates endpoint) – converts the user’s utterance into a TF-IDF vector and finds N candidates with highest cosine similarity among TF-IDF vectors of text chunks.
Skills:
- LLM-based Q&A on Documents Skill – feeds the prompt and N text chunks into a language model as a prompt to generate a response.
Candidate Annotators:
- Combined Classification — annotator for topic classification, dialog acts classification, sentiment, toxicity, emotion, factoid classification;
- Sentence Ranker – ranges the candidate-responses based on their semantic similarity to the user’s request.
Let’s create our bot!
Install DeepPavlov Dreamtools:
pip install git+https://github.com/deeppavlov/deeppavlov_dreamtools.gitClone Dream repository:
git clone https://github.com/deeppavlov/dream.gitGo to cloned repository:
cd dreamCreate a distribution from Document-based LLM QA:
dreamtools clone dist my_prompted_document_based_qa
--template document_based_qa
--display-name "Prompted Document-Based QA"
--author deepypavlova@email.org
--description "This is a primitive dialog system that can answer your questions about the documents. It uses OpenAI ChatGPT model to generate responses."
--overwrite
dreamtools add component components/sdjkfhaliueytu34ktkrlg.yml
--dist my_prompted_document_based_qaOptional; run if you will be using GPT-4
dreamtools add component components/jkdhfgkhgodfiugpojwrnkjnlg.yml
--dist my_prompted_document_based_qaOptional; run if you will be using text-davinci-003
dreamtools add component components/lkjkghirthln34i83df.yml
--dist my_prompted_document_based_qaIn assistant_dists/my_prompted_document_based_qa/docker-compose.override.yml, add file server as one of the containers. Just paste the following lines in the end of the file, right before version: '3.7' (mind the tabulation!):
files:
image: julienmeerschart/simple-file-upload-download-server
version: '3.7'In the same file
assistant_dists/my_prompted_document_based_qa/docker-compose.override.yml, doc-retriever container, replace
environment:
SERVICE_PORT: 8165
SERVICE_NAME: doc_retriever
CONFIG_PATH: ./doc_retriever_config.json
DOC_PATH_OR_LINK: http://files.deeppavlov.ai/dream_data/documents_for_qa/test_file_dream_repo.html,http://files.deeppavlov.ai/dream_data/documents_for_qa/alphabet_financial_report.txt,http://files.deeppavlov.ai/dream_data/documents_for_qa/test_file_jurafsky_chatbots.pdf
PARAGRAPHS_NUM: 5
FILE_SERVER_TIMEOUT: 30
%with
environment:
- FLASK_APP=server
- CUDA_VISIBLE_DEVICES=0
Now, let’s change the documents to the ones you want to use. There are two ways to specify the document: as a link to the file so that the chatbot will have to download it or as a file in documents/ folder. Go to
assistant_dists/my_prompted_document_based_qa/docker-compose.override.ymlI will use two files uploaded to DeepPavlov file server – a paper about LLaMa model by Meta and a post about Aplaca model by Stanford CRFM. I will replace the default links in DOC_PATH_OR_LINK with new links so that it looks the following way:
DOC_PATH_OR_LINK: http://files.deeppavlov.ai/dream_data/documents_for_qa/test_alpaca.html,http://files.deeppavlov.ai/dream_data/documents_for_qa/test_llama_paper.pdfIf you want to provide your own link(s), you will simply have to replace all the default links in DOC_PATH_OR_LINK with your own one(s) as:
DOC_PATH_OR_LINK: http://link_to_file_1,http://link_to_file_2If you want to provide file(s), put the file(s) into documents/ folder and provide the relative path to them in DOC_PATH_OR_LINK as:
DOC_PATH_OR_LINK: documents/your_file_1.txt,documents/your_file_2.pdf,documents/your_file_3.htmlImportant: in both cases, if you are using several links or files, they have to be separated by a comma and no whitespace!
Important-2: as of now, only txt, pdf and html formats are supported. We process html documents with BeautifulSoup (MIT license) and pdf documents with pypdfium2 (Apache2.0 license), keeping the distribution free for potential commercial use.
In a separate terminal tab, run:
docker-compose exec agent python -m
deeppavlov_agent.run agent.debug=false agent.channel=cmd
agent.pipeline_config=assistant_dists/dream_tools/pipeline_conf.jsonOptional; If you want, you may change the generative model in use. By default, we are using ChatGPT (GPT-3.5 based). You may change it to GPT-4 or text-davinci-003 (also known as GPT-3.5). Theoretically, it is also possible to use open-source free models, but they don’t perform well on this task. To change the model, go to assistant_dists/my_prompted_document_based_qa/docker-compose.override.yml and replace the following code:
openai-api-chatgpt:
env_file: [ .env ]
build:
args:
SERVICE_PORT: 8145
SERVICE_NAME: openai_api_chatgpt
PRETRAINED_MODEL_NAME_OR_PATH: gpt-3.5-turbo
context: .
dockerfile: ./services/openai_api_lm/Dockerfile
command: flask run -h 0.0.0.0 -p 8145
environment:
- CUDA_VISIBLE_DEVICES=0
- FLASK_APP=server
deploy:
resources:
limits:
memory: 100M
reservations:
memory: 100MFor GPT-4
openai-api-gpt4:
env_file: [ .env ]
build:
args:
SERVICE_PORT: 8159
SERVICE_NAME: openai_api_gpt4
PRETRAINED_MODEL_NAME_OR_PATH: gpt-4
context: .
dockerfile: ./services/openai_api_lm/Dockerfile
command: flask run -h 0.0.0.0 -p 8159
environment:
- FLASK_APP=server
deploy:
resources:
limits:
memory: 500M
reservations:
memory: 100MFor text-davinci-003 (GPT-3.5):
openai-api-davinci3:
env_file: [ .env ]
build:
args:
SERVICE_PORT: 8131
SERVICE_NAME: openai_api_davinci3
PRETRAINED_MODEL_NAME_OR_PATH: text-davinci-003
context: .
dockerfile: ./services/openai_api_lm/Dockerfile
command: flask run -h 0.0.0.0 -p 8131
environment:
- FLASK_APP=server
deploy:
resources:
limits:
memory: 500M
reservations:
memory: 100MOptional; If you replaced the generative model, you will have to complete this step as well. In the same file assistant_dists/my_prompted_document_based_qa/docker-compose.override.yml, find WAIT_HOSTS, and replace openai-api-chatgpt:8145 with openai-api-davinci3:8131 (for text-davinci-003) or openai-api-gpt4:8159 (for GPT-4).
Optional; If you replaced the generative model with text-davinci-003, you will have to complete this step as well. In the same file assistant_dists/my_prompted_document_based_qa/docker-compose.override.yml, change GENERATIVE_SERVICE_URL and GENERATIVE_SERVICE_CONFIG fields to http://openai-api-davinci3:8131/respond and openai-text-davinci-003-long.json. If you replaced the generative model with GPT-4, skip this step.
Go to asisstant_dists/my_prompted_document_based_qa, create proxy.yml, and paste the following code there:
services:
combined-classification:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8087
- PORT=8087
sentseg:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8011
- PORT=8011
sentence-ranker:
command: ["nginx", "-g", "daemon off;"]
build:
context: dp/proxy/
dockerfile: Dockerfile
environment:
- PROXY_PASS=proxy.deeppavlov.ai:8128
- PORT=8128
version: "3.7"Optional; You can change the text of the prompt to alter the way the model answers your questions. To do that, go to common/prompts/document_qa_instruction.json and edit the original text in the "prompt" field. Just for fun, I will add “You must always talk like a pirate.” as the final line of the prompt.
In dream directory, create file .env_secret and add your OpenAI API key there in the following format:
OPENAI_API_KEY=Finally, build your distribution:
docker-compose -f docker-compose.yml -f
assistant_dists/my_prompted_document_based_qa/docker-compose.override.yml -f
assistant_dists/my_prompted_document_based_qa/proxy.yml up --buildIn a separate terminal tab, run:
docker-compose exec agent python -m deeppavlov_agent.run agent.channel=cmd
agent.pipeline_config=assistant_dists/my_prompted_document_based_qa/pipeline_conf.json
agent.debug=falseEnter your username and have a chat with your question-answering Dream!
(remember, in this tutorial we made him talk like a pirate)
(remember, in this tutorial we made him talk like a pirate)

Useful links
- Dream Website
- Dream on GitHub
- DeepPavlov Discord
- Dream FAQ
- Creating Assistants with DeepPavlov Dream. Part 1: Distribution from Existing Components
- Creating Assistants with DeepPavlov Dream. Part 2: Customizing Prompt-based Distribution
- Creating Assistants with DeepPavlov Dream. Part 3. Task-Performing Distribution with Reasoning and API Integration
- Building Generative AI Assistants with DeepPavlov Dream
- Prompting For Response Generation: Which LLM to Choose to Build Your Own Chatbot